

AI Dementia—Why Your Agent Gets Progressively Dumber As You Talk To It
What is context rot and how does it change how you should use AI


In the Halo series, one of the plot points is that the AI eventually becomes “rampant.” (Yes, I mean the shooter game—believe it or not, it not only has a plot, it has a pretty good one if you include the books.)
Humanity’s AI in the game, by most any definition, is AGI. However, far from being immortal, they have a far shorter lifespan than humans—around seven years. After that period, with all the trillions of data points and thoughts it has, it literally “thinks itself to death” and goes insane: rampancy.
When I was younger, I thought that was a dumb mechanic. Little did I know, our modern AI would look very similar to it—except its lifespan is in tokens.
How does this matter?
I was inspired to write this article after speaking with various people and getting shock and confusion when I casually mentioned that, “Of course, that’s why you need subagents—AI gets dumber as you talk to it.”
It’s quite obvious to me as someone who has played with language models since their very earliest days. Back then, when you kept the chat going for too long, you could easily encounter deranged behavior like completely random swearing or looped text (like Jack Nicholson in The Shining). Or you just got a hard stop—Anthropic did it especially jarringly, where Claude would suddenly display an error saying the conversation was too long and start a new one.

It was one of the reasons why I found ChatGPT so clever in its user experience. Obviously, they somehow trimmed the conversation in the background—ChatGPT would forget random things. But it all felt pretty seamless.
It was one of OpenAI’s clever “tricks” that was less a technical triumph and more a hack (especially versus the more snooty “pure” approach favored by Anthropic) that nevertheless made it feel magical to normal users.
Nevertheless, every model had this issue. And they still do.
The Context Window
In order to understand this concept, you have to understand that LLMs do not “learn” as you talk to them.
They don’t actually “learn” at all in a traditional sense—I call them “know-nothing machines” in my book What You Need to Know About AI in part because they really just know “word” (token) associations. But putting that aside…
They did all of their learning during “pre-training” where huge amounts of text (and now other modalities as well) are fed into them. The text is broken up into “tokens” (bits of text that are, on average, a bit less than a word) and then massive numerical vectors are constructed to represent their meaning, and then the probability of tokens following one another is trained into a model’s weights.
That pre-training (and work tuning those weights afterwards) is frozen for all of your chats with the AI. If you’d like, that’s the AI’s intelligence/personality/etc.
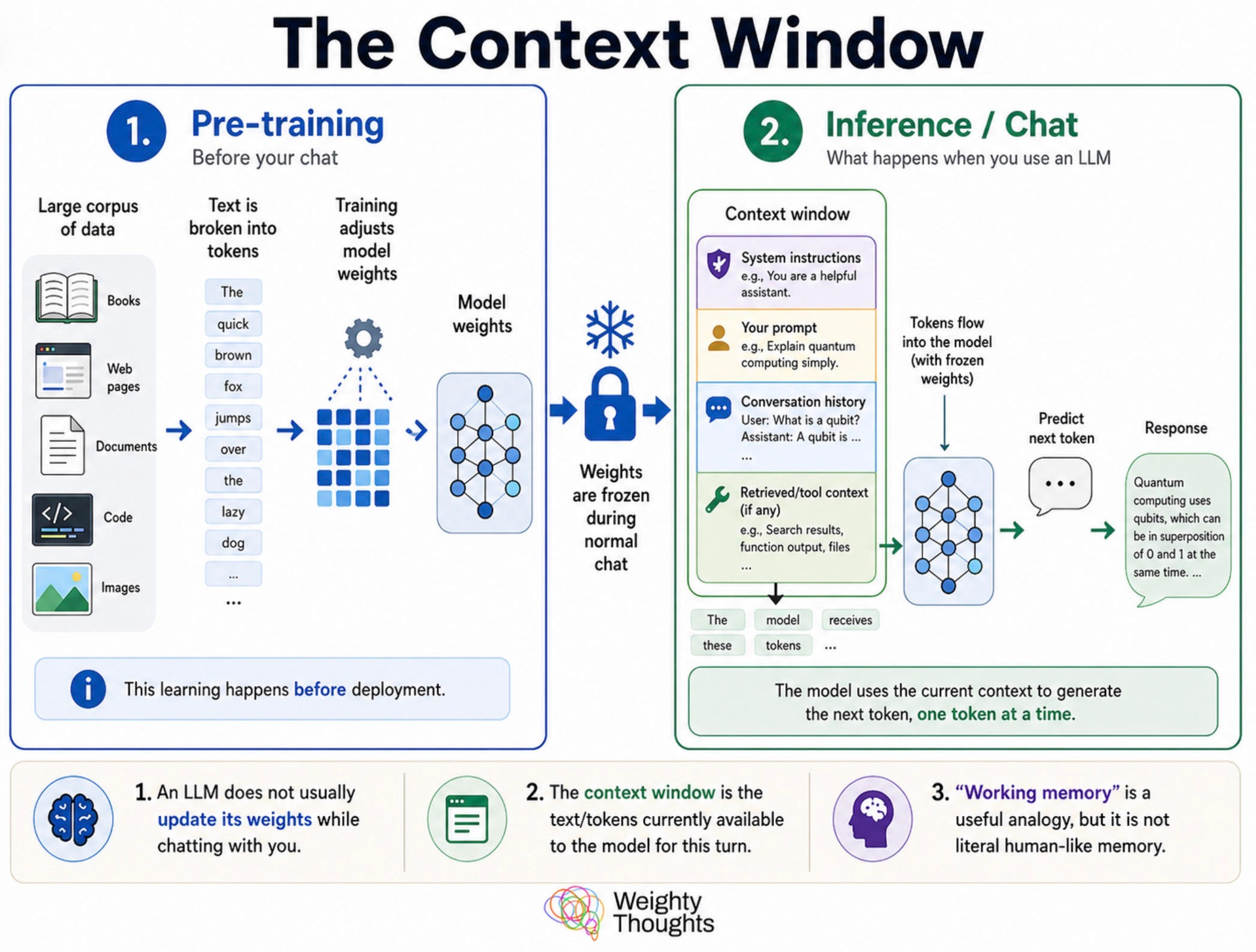
What you are operating in is the context window, which is often described as an AI’s “working memory.”
That analogy is ok but it obfuscates what LLMs really are and anthropomorphizes them. They are fancy (and amazingly good) autocomplete machines—like what you see on your smartphone when you’re typing out messages. An LLM writing out a message is kind of like you constantly just hit the next predicted word over and over again.
A really, really good autocomplete should consider all words that came before it, which an LLM does. An absolutely unbelievably good one will even emulate following instructions because that’s what a person might have written out!
The context window is the maximum number of words the system will allow you to consider before it runs out of “space” to do so. Or, perhaps more specifically, the words grow so numerous that it can no longer consider all of them.
This is why models also publicize the size of their context windows. While they started quite small with just thousands of tokens, now models like Claude Opus can take in a million tokens.
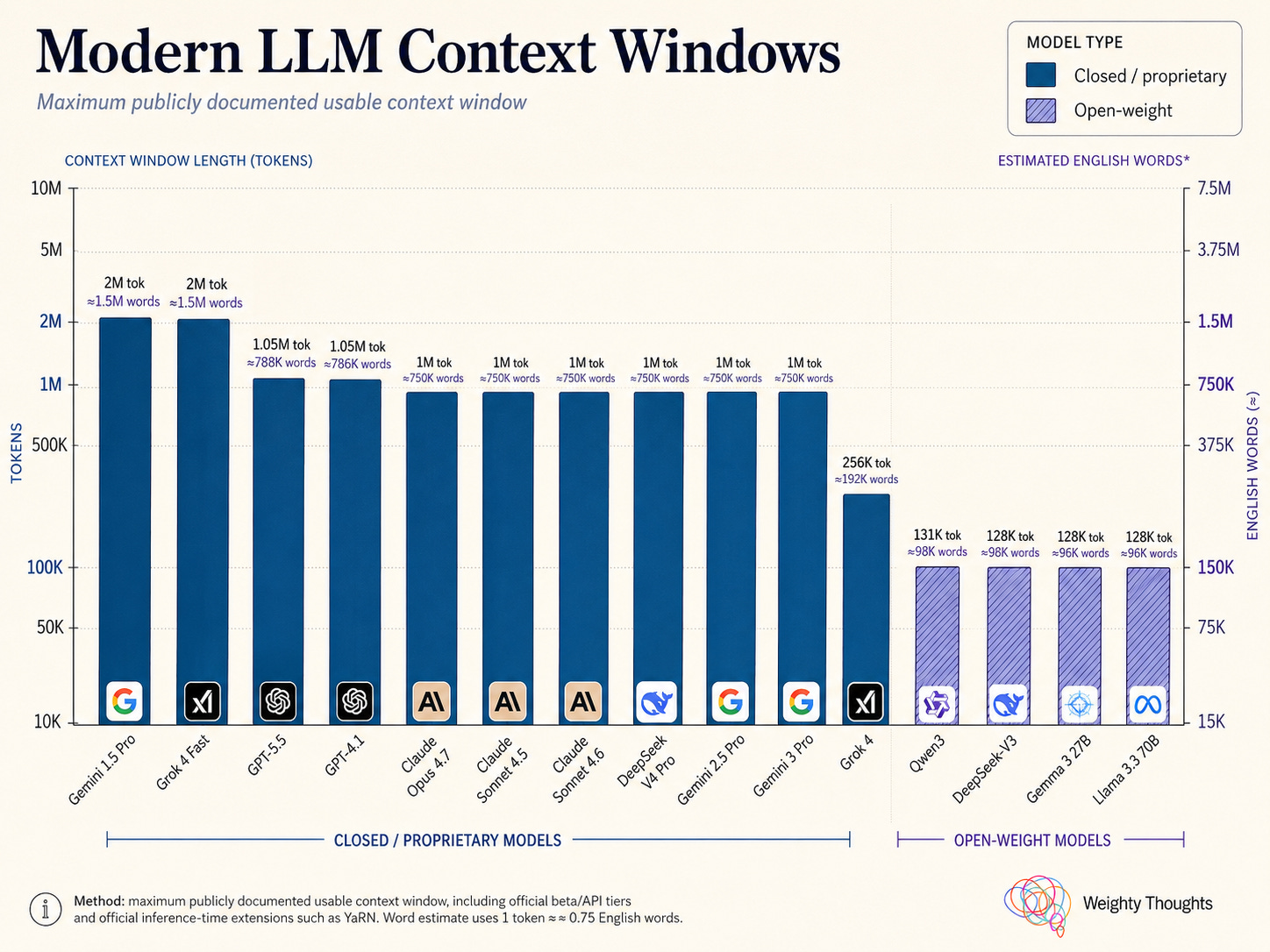
But just because you can doesn’t mean you should.
Context Rot
In general, the “rule of thumb” is that you want to avoid filling up 50% of the context window. That works fairly well, but performance degrades surprisingly quickly.
All of the models below have context windows stated to be in the hundreds of thousands (or even millions). We see noticeable performance degradation well before that.
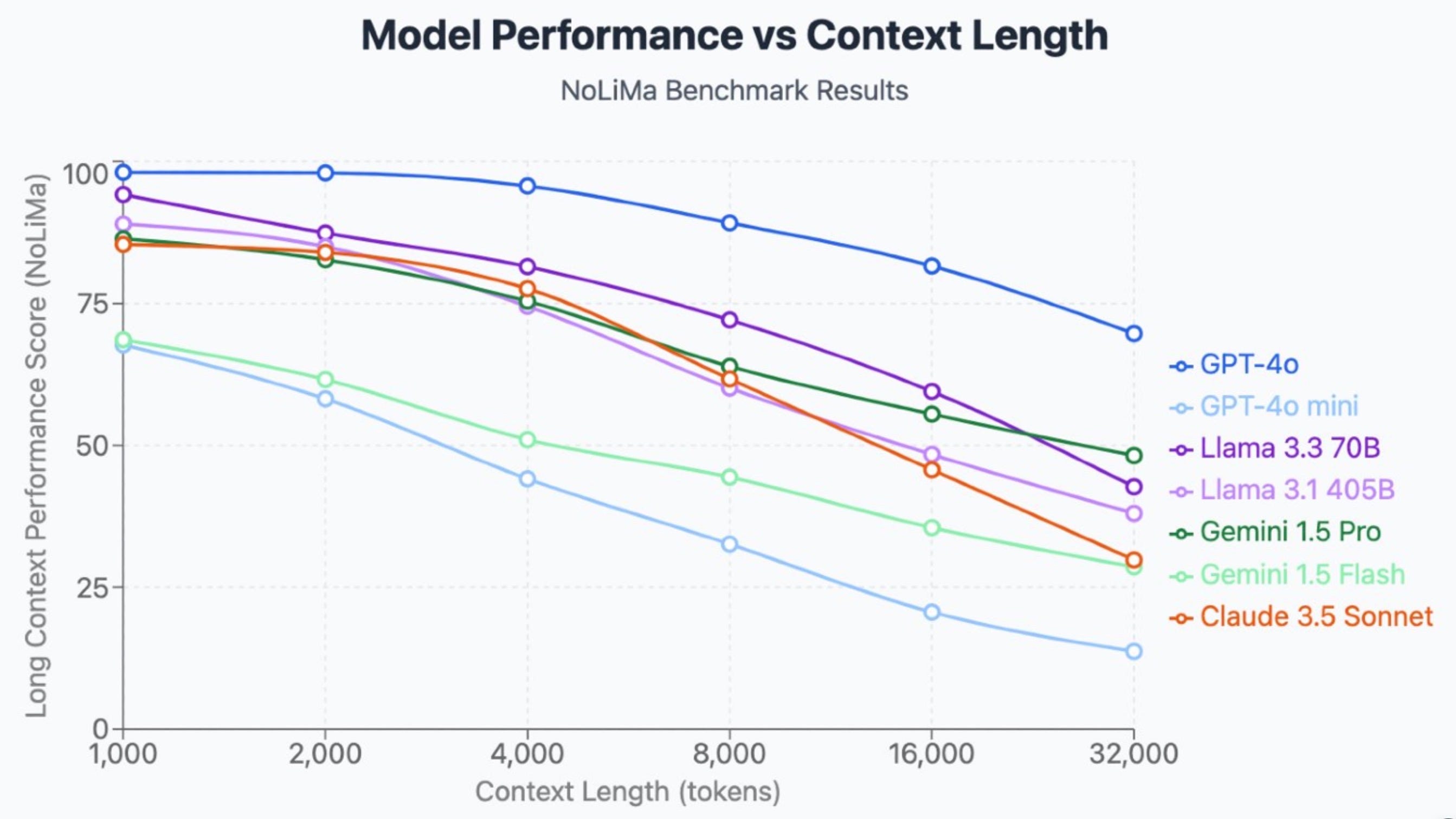
If you want to dig into it more, you can see the advertised length (“Claimed Length”) and what this particular paper stated as the “Effective Length” based on scores on their benchmark. All of the effective lengths are much shorter than 50% of the model’s claimed length. In fact, they all tend to cluster around a couple thousand tokens.
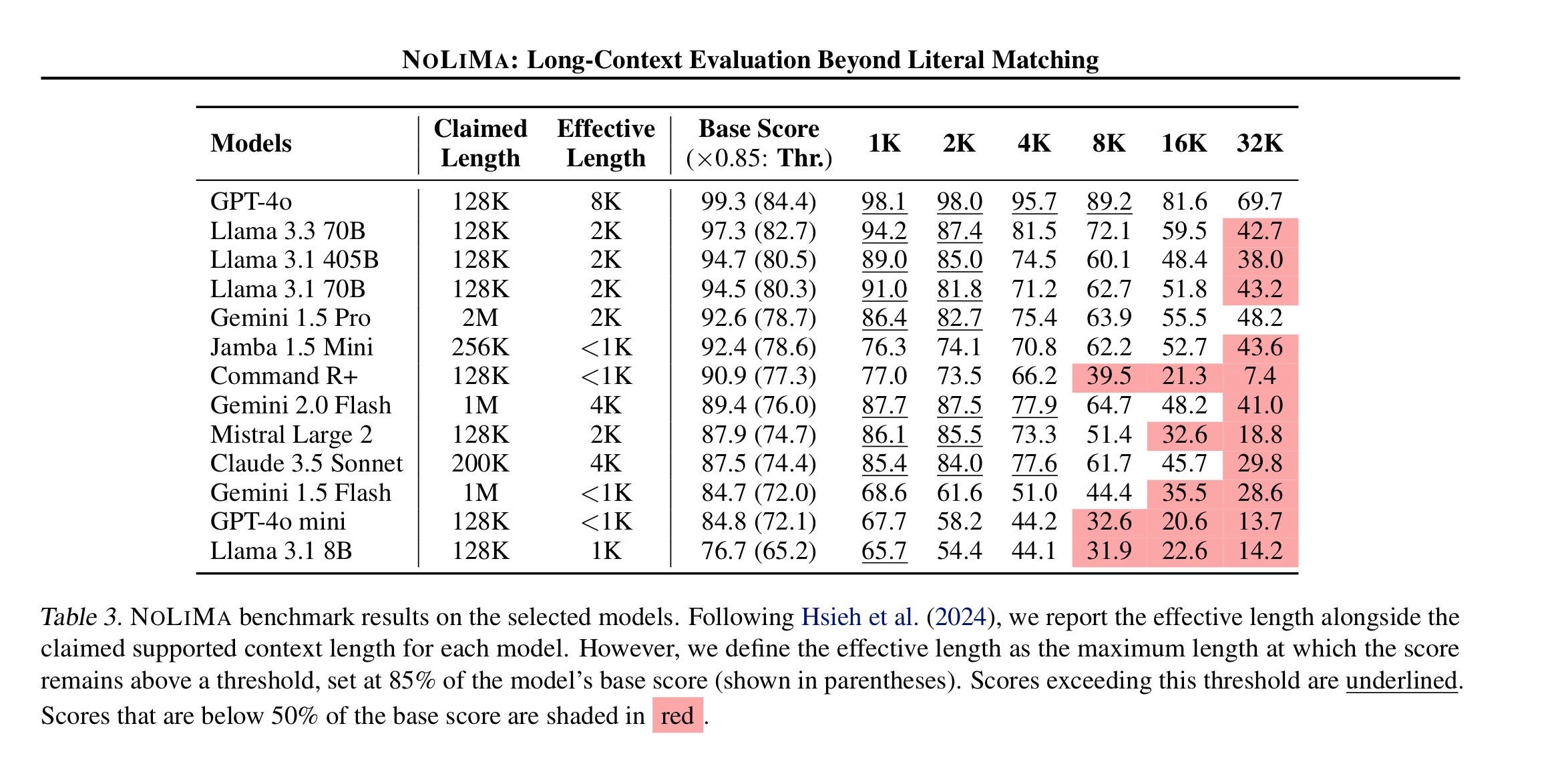
One might quibble with how the author of the papers created their benchmark. It is specifically “finding a needle” in a haystack of text. That is pure retrieval from the context window—not instruction following, reasoning, or “intelligence.” One can argue that the benchmark is unrealistic or even unuseful.
However, one can argue that if the LLM can “forget” things so quickly in such a short window, we should expect a meaningful degradation in the results we’d see from an agent. If you want to make it an intuitively “human” analogy, it can simply be the length of context before an agent is “overwhelmed” and starts forgetting things.
Hence, for our purposes, poorer instruction following, forgetting key context, more hallucinations… which we can collapse to “dumber.” Exactly why this happens is not precisely known (we have reasonable theories), but for our purposes, it only matters that the behavior is consistent across models.
I’d say from experience that 50% is a more useful target “keep under” than this specific benchmark. That being said, it illustrates the point fairly clearly.
So what does this mean?
If you have meaningfully difficult work, you should break it up into very specific and focused subtasks. You can obviously do this manually, but from something like Claude Code/Cowork or ChatGPT Codex, you can dispatch subagents.
These are like opening new, fresh chat windows, except in this case the AI can do it for you and give them the specific tasks.
The how is easy—just ask it to dispatch subagents to do each individual task and keep your “main” context purely for planning and coordination of the subagents. As in, “dispatch subagents to research each topic and summarize it back to you.” (Again, this only works in a context like Claude Cowork or Code, not a normal chat window)
This also means that trying to have a long running chat window or agent is a huge mistake. I’ve heard a lot of people now do this (which sounds insane to me with my early-LLM habits). They think that you’re “storing” knowledge that makes the AI better over time. In reality, it’s at best forgetting the old information—at worst, it’s basically becoming unusably “dumb” with poorer and poorer performance.
(Something fun to keep in mind: this is a challenge for the AGI through big-enough-LLM path. Maybe the right way is separate architectures for a “mind engine”—like the LLM—and long term memory, but either way, without a clear solution to this, an “AGI” whose lifespan is less than a million words is not exactly either the AI messiah or Terminator.)
What’s the right way to store lots of knowledge then?
This is a funny sentiment given LLMs, in contrast with the prior generation of AI (“Knowledge-Based AI” or symbolic AI) from the 1980s was all about knowledge—which proved itself to not have enough flexibility to be economically valuable. Nonetheless, the canonical answer for today’s AI is RAG. Retrieval-Augmented-Generation.
It’s an industry term for systems that give an LLM precisely the right knowledge for generating its response—and only that knowledge. It’s almost like having it do a precise Google search of the information (though more sophisticated) first.
That’s kind of difficult to put into practice and a lot of “RAG” solutions are built for giant corporate knowledge bases. Not only are they difficult to deploy and likely overkill for most individuals… it is also not very good at doing what most people want, which is to make an AI agent “smart” about a specific context area.
That’s why I made my own pattern for it, which I’ve called knowledge agents. If you’re interested in me writing about my implementation, let me know!
(In the meantime… maybe I’d be better at growing my audience if I were more a click-baiter, but I just hate dropping annoying cliffhangers. If you’re interested in looking at it before a walkthrough article, my open sourced implementation is here.)
Thanks for reading!
I hope you enjoyed this article. If you’d like to learn more about AI’s past, present, and future in an easy-to-understand way, I’ve published a book titled What You Need to Know About AI.
You can order the book on Amazon, Barnes & Noble, Bookshop, or pick up a copy in-person at a local bookstore.

You've outdone yourself on this one, James. Simple, straightforward, useful, and interesting on multiple levels. Nice job!
Great work- inspired some thoughts on 'context rot' and AI therapy bots- which you can find here.
https://charlesbgross.substack.com/p/ai-gets-dumber-as-you-talk-to-it?r=28f66