

Compute is Overrated as AI’s Bottleneck
You can’t just blindly extrapolate compute requirements

Humans are terrible at understanding what lies at the end of an exponential curve. We both vastly overshoot and undershoot in our expectations, but both are usually because we are very poor at predicting what stays the same and what changes.
Malthusians have been predicting that humanity would run out of food and die miserable deaths from overpopulation simply by following the exponential curve of population growth upwards. They failed to adjust for rapid improvements in agriculture technology… and failed to predict that human population growth would naturally level out as societies grew wealthier.
On the other hand, everyone in the 1950s expected flying cars and the Jetsons by now (we’re decades overdue).

If you follow the current exponential curve of AI training system requirements, we quickly get to ridiculous levels. A few analyst reports have speculated that by 2035 the cost of training AI systems may exceed US GDP.
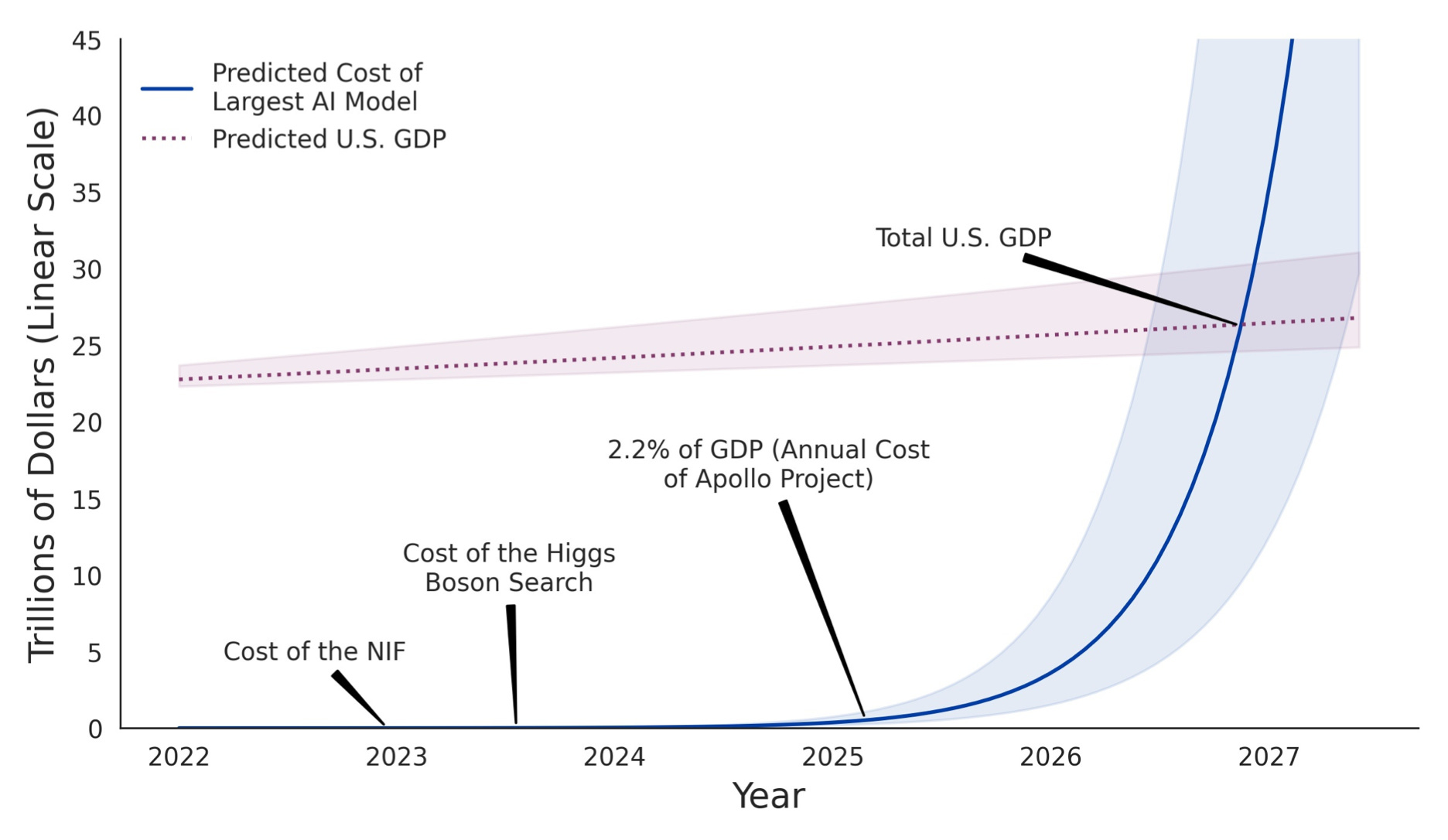
This, of course, is silly.
We wouldn’t do that. Even if that were possible by government fiat, we’d never starve children, stop producing cars, etc. to train ChatGPT-18
US GDP (and the world’s GDP) would rapidly increase if AI generated massive productivity improvements. We likely would have much more to work with, assuming these systems were actually worth training.
That’s just not how AI is likely to work. More data and more compute certainly improves almost any AI system, but the massive difference in AI in the early 2010s and today is not just from—or even primarily from—data and compute.
The latter point is the most interesting, so we’ll focus on it here.
AI’s big leaps have come from doing more with less
Artificial intelligence is a rather loaded term. What we are dealing with today is machine learning—more descriptively termed statistical learning.
That can help us understand what is actually going on.
We’re actually just doing what every high school student does with linear regression. Take some data. “Fit a line.” In this case, the line is a distribution with potentially thousands of dimensions instead of two.
Yeah, hard to visualize, but not magic.
In later statistics classes, students learn that you can fit other kinds of lines instead of just a straight line. If the underlying data is exponential (curved upwards), an exponential curve would fit it better. You can never fit a straight line to it.
If you intended to fit straight lines to that data, you could use hundreds of linear regressions and switch to different ones that fit better as you went. In theory, if you used infinite lines, this could work. However, this is just brute force of learning every data point.
OUR ADVANCEMENTS HAVE COME FROM BETTER MODELS
One of my favorite charts is the ImageNet benchmark showing that computer vision reached human performance levels around 2015.

This wasn’t achieved by just throwing more data at the problem (which wouldn’t work here anyway—the data is fixed). It was achieved largely by improvements in convolutional neural networks (CNNs). Basically, something closer to using a better kind of line to fit the data, versus brute force.
.")
This is a bit oversimplified but similar to the example with the straight line, we’d never be able to recognize images by feeding straight-up image pixels into larger and larger models.
That would be brute force, but to reliably recognize something as simple as a cat, we’d need every possible iteration of cat, in every possible orientation, in every possible situation with that brute force technique. CNNs instead “move the image around” and do some level of generalization to recognize certain classes of objects reliably.
The ultimate goal of artificial intelligence (actual AI) is to resemble what human intelligence can do more closely. A human being (like a toddler) who’s never seen a cat probably doesn’t need millions of cat photos to recognize a cat reliably. A few photos—three to five… or even one—is likely sufficient.
CHATGPT IS POSSIBLE BECAUSE OF TRANSFORMERS AND LLMS
ChatGPT, Bard, LLaMA—all of these are examples of models built on large language models, based, fundamentally, on transformers (“Attention is All You Need” Vasani et al, 2017).
Transformers were an innovation on top of CNNs that could better scale and fit the structure of human grammar better. Like the previous point, ChatGPT would have never been possible by just feeding in massive amounts of data.
What marginal data will even come next?
ChatGPT and its ilk all (in)famously grabbed essentially all text on the internet they could access.
DALL-E, Midjourney, and Stable Diffusion did the same with images.
Though less well-known, generative AI for text-to-voice and video have done similarly in their respective fields.
The internet will continue to grow. But:
How many times will you feed in “the entire internet’s X type of data?” (Not constantly. It doesn’t apply for everything, but a lot of models can use “checkpoints” and just feed in incremental data anyway)
How many domains are left to “harvest” from the internet?
Finally, how much better will these models actually get with even more data? (We’re clearly already hitting some level of diminishing returns)
This may sound like I’m saying “We’re out of data to train on.” That couldn’t be further from the truth. There are massive domains of data that are more valuable to train on than what we currently have.
Medical data, chemical/pharmacokinetic data, material science data, etc. all have a lot of potential to be used. They’re all generally more complicated than human grammars and have many more less explicit rules (“hidden nodes” or rules of human physiology, quantum physics, or similar that we simply don’t understand).
However, these kinds of data can’t just be web scraped, and will be much more expensive to gather.
As such, the bottleneck as we go won’t just be computational ability to run data, but we’ll need to stretch harder to gather data from domains where it isn’t just freely available. (Separately, practitioners are starting to ask how much AI-generated writing, images, etc. will start to “poison the well” that these generative models draw on. It’s an interesting question, but a topic that would be too long to delve into here).
Gains will become marginal after a point
One of the most famous papers in the AI field is, “The Unreasonable Effectiveness of Data” (Halevy, Norvig, Pereira 2009). The central point of the paper is that even “dumb” models like memory-based (essentially brute force) could keep improving given massive quantities of data.

Many other papers have built on this point where “performance keeps scaling, so long as it gets more data.”
This seems to counter my point above, but I think it’s actually extremely useful to demonstrate why we’re reaching an “endpoint” to just using more brute data (and, in effect, more compute to train that brute quantity of data).
If you look at the chart from the paper, accuracy is starting to level off but approaches 100%. In the ImageNet benchmark I had at the beginning, you notice that achieving human levels of performance means having a less than 5% error rate (95%+ accuracy).
In certain fields, 99.999999% is desirable and valuable. In many others, you quickly hit diminishing returns as accuracy levels off (if nothing else, from asymptotically approaching 100%). You won’t be willing to pay 10X to achieve another 0.1% improvement in accuracy, though it may start to cost that much to do it.
We’re already seeing generative models be “pretty good” for many simple (and not-so-simple) prompts people are throwing at them. Further levels of creativity that some users expect from the models are simply technically impossible given the underlying architecture.
To oversimplify, the best these models can do is what a “talented intern” can—synthesize well from the best sources the intern finds online. They aren’t currently capable, given how transformers work (even with “hallucinations”) to actually be creative. So, form letters, legal documents, and “talented undergrad editor” help in writing a novel is impressive, but likely reaching the limits of where this specific iteration of tech can go.
So, does that mean hardware is a dead end?
I’m not going to be the apocryphal Bill Gates in the 1980s who said, “640Kb of memory should be enough for anyone” (there’s no actual evidence he said that).
As we get more compute capacity, I can guarantee we’ll find productive ways of using it. To say otherwise, I’d be falling into the opposite trap of exponential failure of imagination that I’m criticizing—I would be assuming that we’ll “level off” based on reasonable limits of our current technology and not find new innovations from here.
I’m just saying that declarations of doom and insane extrapolations of how much it will cost to train AI are deeply flawed.
It’s inherently difficult to predict what breakthroughs and especially exponential technological improvement will bring—which is where we are in AI.
As I stated in the beginning: humans are very bad at understanding what’s at the end of an exponential curve. No thinker at the turn of the 20th century would have been able to predict the world we lived in at the end of the 21st.
Semiconductor advancements have boggled the human mind in terms of the sheer speed in which they’ve developed. We’ve gone from people disbelieving that we could ever have affordable pocket calculators to semiconductors existing in practically every modern object. Your dishwasher or flashlight can probably do more computations than the most powerful early supercomputers (let alone what your smartphone can do).
What will create the next AI frontier?
Substantive improvements are dictated largely by bottlenecks. If you double compute for the same cost today, you won’t get double the performance of today’s models (assuming you could even properly measure “performance”).
The next frontier of AI shock and awe is more likely to come from the upcoming techniques and models already being developed today. Personally, I’m still watching deep reinforcement learning, better methods of generating synthetic data, and advancements in generative adversarial networks (incorporating our leaps ahead on the generative side). As such, I’m expecting the true pace of practical uses of AI technology to be dictated by the pace of AI itself, not specifically compute.
By the way, that doesn’t mean I’m a pessimist about the speed of AI—especially given that “true” Moore’s law has been dead and buried for decades now and compute has harder limits than AI techniques/algorithms. If anything, I’m an optimist.
New businesses will be enabled and how human beings live will be transformed in the next few years in ways that no one can imagine.
THAT ALL BEING SAID…
No one can control the speed of AI improvement. It’s being done in the open (open source) and the entire field’s frontier is moving toward by orders of magnitude every few years.
That means that “better AI” is not investable. What is investable is a controllable marginal improvement, even if it’s limited… which actually does bring us back to certain innovations and scaling in physical computing. Most profits here will be captured by the big players (Amazon, Microsoft, Alphabet), but there will be some “thin edges” where startups can jump in.
Yes, I know that sounds crazy given what I’ve said before this, but remember, the pace of the field means improvements in everyone’s life, but not necessarily realizable profits by companies. Moore’s law fundamentally changed human life. The margins of many semiconductor giants were quite thin at many points in history. Hence, investable areas aren’t just dictated by technology but also by market structure.
However, that’s the topic of another article.
What do you think about data teams as bottlenecks? As in, the processes humans are following to do data engineering and AI/ML work
I’ve seen some practices by keepers of the medical data you mention (data vendors and providers), and trust me, there’s some serious work to do with DataOps in that space - which will serve to reduce bottlenecks in systems, and unlock more data to train on, responsibly