

The Fall of Data Moats
AI actually makes most data moats weaker


It’s been a crazy week, so instead of a new piece, this is a repost from January 2021. It’s an oldie but a goodie, though!
One of my themes on this Substack is that despite all of the recent AI hype, a lot of the trends we’ve seen in AI haven’t fundamentally changed. The real turning point was in the mid-2010s when we reached human levels of performance in computer vision, and then we took off from there.
A common saying emerged with that early AI success: “Data is king.” If you’ve read some of my other pieces, I do emphasize the importance of data. But proprietary data, not just masses of data that everyone else can get as well. A lot of generative AI today is using a lot of data—all of it scraped (maybe or maybe not following legal guidelines or Terms of Service…) from the same internet of text, images, and videos everyone else has access to, so this admonition on data moats is still quite relevant today.
Also, thanks for joining being an early reader!
If you have a few minutes, I have a quick survey to learn more about what you’d like to read that I’d super appreciate if you filled out!
Originally published at Creative Ventures.
Data is the new oil: a commodity on its way out
“What is your data moat?” It’s one of the most common questions asked of any AI or data-driven startup.
It’s also an increasingly irrelevant question. Thanks to better representations and algorithms it’s now possible to do a lot more with a lot less data. Outside of a limited number of fairly specialized applications, data moats are becoming less and less secure.
It’s worth looking back at the history of big data not only to better understand how we got here but also to help identify those increasingly rare circumstances where data moats continue to create defensibility.
Defensibility Through Data
Data moats aren’t a new thing. In the internet age, they stretch all the way back to Amazon (the e-commerce bookstore) having ambitions of capturing general consumer purchasing behavior. Even before the internet became ubiquitous, IBM had vendor data lock-in and specific data on customer business requirements.
Defensibility through mass quantities of data really took off around 2010 as progress in machine learning/AI began to accelerate. Starting in 2015 breakthroughs from convolutional neural networks and other techniques increased opportunities for practical applications of AI, increasing the need for large data troves and data-network effects.
The irony of this data land grab is that many of the same breakthroughs that enabled practical applications of AI/ML have introduced innovations that make massive data sets less and less valuable.
Before getting into that though, let’s discuss why mass quantities of data have been so treasured that investors once regularly funded companies that did nothing but collect data.
The Unreasonable Effectiveness of Data
In the not so recent past, when given the choice between a better model or more data, you’d have been smart to take more data.
On the one hand, you could carefully interview experts in a specific application area and find the best engineers to carefully craft the best algorithm. In contrast, you could simply dump a massive amount of data into an off-the-shelf algorithm—one that didn’t even fit the assumptions of the problem area—and very likely outperform the better model trained on less data. Even worse, when sophisticated and simplistic models were both trained on extremely massive data sets, they performed more or less equally.
This was pretty much the finding in Michele Banko and Eric Brill seminal 2011 paper. Given the natural language task of figuring out what was the appropriate “disambiguated word” (e.g. principal vs principle), Banko and Brill found that more complex models that took into account some aspect of grammar/structure really didn’t do substantially better than an extremely simplistic/dumb “memory” learner that just literally memorized the words before and after a word.
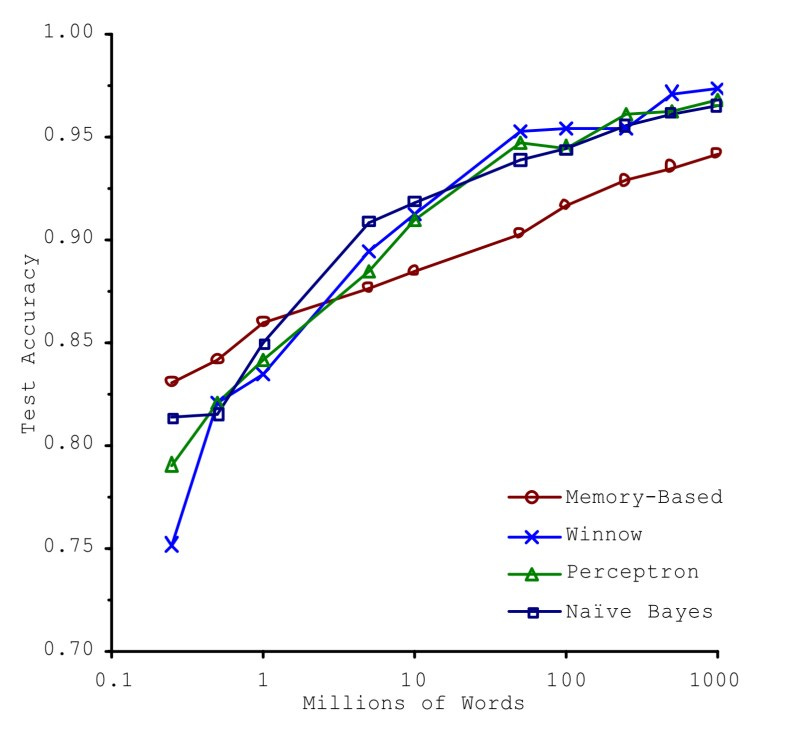
The more complicated models eventually did better, but we didn’t actually see model choice making a huge difference. And, in fact, the really dumb model was still in the ballpark of accuracy even if it didn’t do as well when trained on the largest data set. This is the core insight behind Peter Norvig’s widely quoted (and misquoted) paper “The Unreasonable Effectiveness of Data.” 1
So, why isn’t data still king?
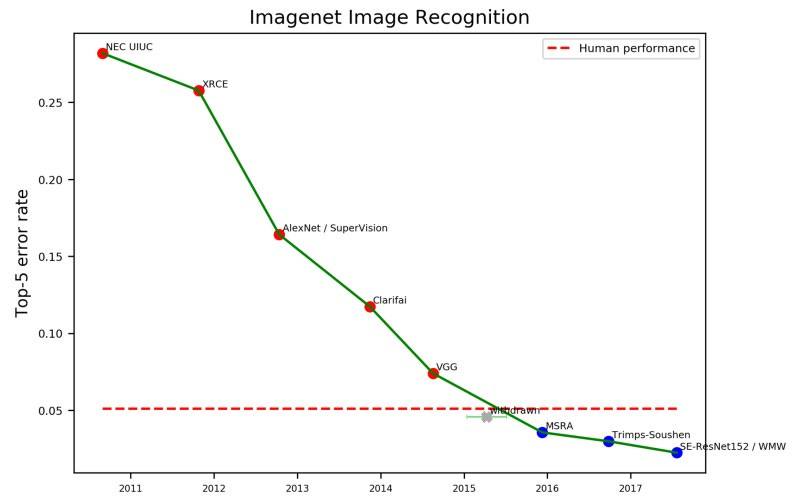
It’s because innovations in representation and algorithms. The ImageNet performance chart embedded above. illustrates that, around 2015, we started to see the ability of machine-based image recognition reach human levels of accuracy.
Since then, of course, we’ve had things like AlphaGo beating the human world champion in Go. Or AlphaStar doing the same in StarCraft II.
We’re essentially seeing something that’s been predicted since the 1980s: machine intelligence—in more and more general ways—is finally starting to match or exceed human performance.
It’s worth understanding why. Are the many advances in computer vision the result of data sets growing that much larger? Are AlphaGo and AlphaStar just mass-mining game data to beat the best players?
The answer is no, and no.
If we really sat around hoping that we’d get enough data to be able to recognize a cat from pixels, we’d need billions of examples with cats in all kinds of orientations, environments, and contexts. Similarly, if we wanted AlphaGo to use mined data to beat a human player, we’dneed to have an exponentially, impossibly larger data set exploring almost every iteration of the game board—which works in the more bounded chess, but not in Go (let alone StarCraft).
When it comes to image recognition, what we actually got were CNNs (convolutional neural networks), which “convolve” or “move around” images in a lot of ways, and feed them into a neural network that “compresses” data by throwing out overly specific data and retaining more generalizable data.
On the AlphaGo/AlphaStar side, they didn’t use “real” data at all. Both algorithms essentially played themselves over and over and over again, and used deep reinforcement learning to synthetically generate “data.” Simply put, Alpha Go and Alpha Star taught themselves how to play these games.
In neither case are the algorithms either hand-tuned like the laborious crafted algorithms I described above (which most closely resemble “expert networks” from the 1980s and 1990s) or reliant on ridiculously large datasets..
The advances we’ve seen are the result of CNNs (a combination of representation and models) and—in the case of AlphaGo/AlphaStar—advances in synthetic data.
From an investor and, well, just human perspective, it’s really exciting that we no longer have to hand-craft algorithms as much because if that were the case using AI/ML to solve real-world problems would never have worked at scale.
The fact is that these seminal breakthroughs didn’t rely on more data. If anything, we got better at using less data. With CNNs we can now do with thousands of data points what once required millions.
And in the future, we’ll likely see similar order-of-magnitude shifts.
Bad news for data moats
If your business is built on the assumption that no one else can catch up to you after you’ve amassed a critical mass of data, you might be in a rough spot. .
It’s true that in the AI/ML business, the idea of building a data moat can make a lot of sense. . Let’s assume:
It takes 10 million data points (say, something non-trivial, like hospital visits) to have a useful prediction from ML
Through giving away your not-so-great product for free (or even pay people to use it) and buying datasets and just manually creating data, you get there first
Now, you are just like any other software business, with near-zero marginal cost. Except in this case, people who want to catch up with you need to also need to do the same thing you did, but you can always undercut anyone who’s willing to go with a not-so-great product.
You can practically give away your product to prevent anyone from getting datasets. And as you keep accumulating data, you might have the ability to do even more, making competition even more lopsided.
You are better, cheaper, and continue to get more and more superior to any potential competition.
Given all this, it makes complete sense why VCs would be willing to fund the kind of business that will have a durable (and growing) monopoly.
Unfortunately, the reality is that representations, synthetic data, and broader machine-learning techniques are decreasing the value of data moats. Meaning you can spend a ton of money to get your dataset today… and a competitor in the near future will be able to match you with an order of magnitude less data.
At some point someone playing around with off-the-shelf libraries will be able to take some toy dataset and rival you.
So what still works? How should you proceed?
Option 1: You don’t need a data moat. Although this would seem to defeat the value of an AI company, there are plenty of other types of lock-in you can rely on: switching costs in a sales-heavy environment, for example.
Option 2: Accrue a dataset will always be extremely niche and somewhat painful to gather. If some researcher might be interested in getting grant funding and running a study with a hospital or something, you may be in for it. Some random part of the hotel/hospitality cleaning process? Well, that seems a bit more insulated from PhDs. Alternatively, bet on data that is specific and can only be collected by your device.
Any big interesting research problem will eventually have some high quality research dataset. A big, huge, general problem will have tons of startups grinding it out to gather data. Some “boring” niche in the industrial universe? That’s safer. Something that requires your super-specialized equipment (or super-specialized equipment in general)? That’s a good deal safer as well.
The lesson here is that applications mean a lot more than algorithms, which is something I’ll say more about in a future post.
The future is one where AIs can learn more like humans
A human infant doesn’t need 10,000 examples of snakes in various orientations, color patterns, and environments in order to figure out what a snake is—which is roughly what a good CNN might need to be able to handle somewhat arbitrary snake data. One, or maybe two, examples will generally suffice.
As a whole, we should expect researchers and engineers to continue to make AI/ML work more and more generally and behave more and more like humans.
Of course, “when” we will actually get to a true general human level is pretty uncertain. In the meantime, we should expect that accruing large quantities of data to become less and less of a barrier to replicating results. If you’re an entrepreneur looking to start a company, it’s worth keeping this in mind. You should be looking to develop an application that either doesn’t need a data moat or that relies on one no one will likely ever bother to challenge.
Footnotes
[1]: For nerds, this is a callback to the 1960s paper “The Unreasonable Effectiveness of Mathematics in Natural Sciences,” where the author essentially muses as to how mathematics had proven shockingly effective in physics (and other natural sciences) in predicting how things work—and where scientific intuition and math collided, math often won. In this case, it’s now data that provides the unreasonable and unintuitive effectiveness.