

Three Macro Predictions on AI
And also a reaction to OpenAI's GPT-5 release


OpenAI just released GPT-5—to great fanfare and mixed reviews around the internet. According to benchmarks and subjective personal testing, GPT-5 is better than GPT-4 and o3.
It’s certainly a better default than GPT-4o, which is what most people used on ChatGPT’s interface. The model dominates across the board in LMArena.
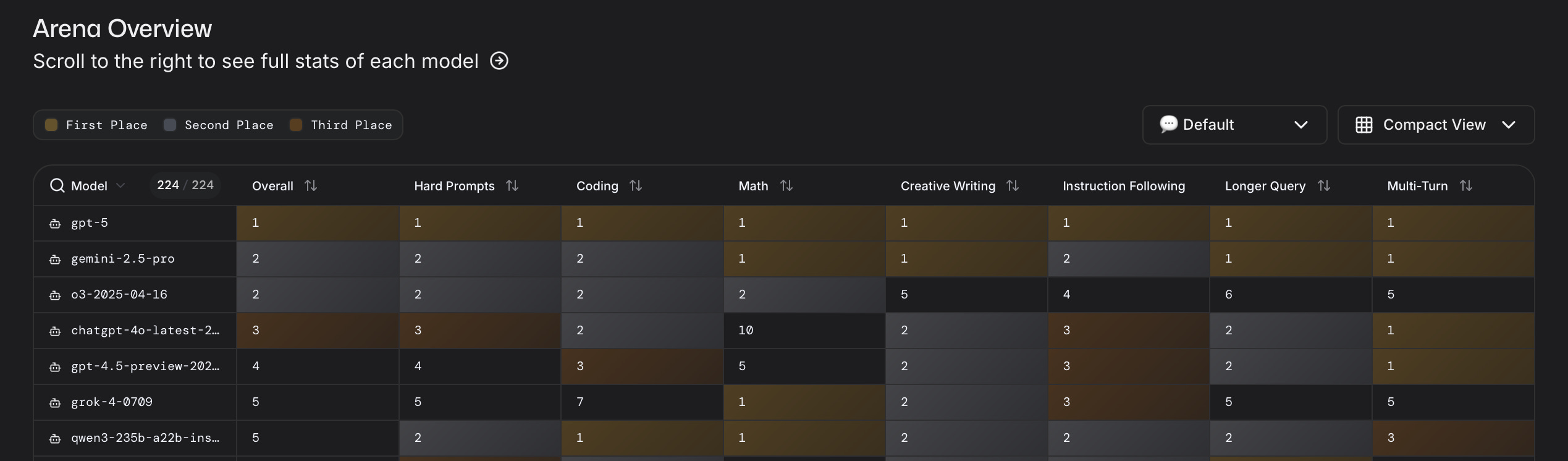
I don’t feel it as much. But I also used OpenAI’s research previews of o3-mini-high, GPT-4.5, and other models for specific tasks. As such, I don’t really see it as revolutionary. That makes sense though. Today, if you try to select other models in the Plus subscription, all you get is GPT-5 and GPT-5 Thinking (the latter being the “high effort” version of the first).
The function of those research previews all got rolled into the 5-series.
Of course, it’s not identical. The tone, for one, is quite different. I didn’t notice as much, but I always took steps to reduce sycophancy. Whenever possible, I wanted it to disagree with me. Other people used it differently.

That makes me feel a little bad calling it sycophancy—even though it’s the industry term. The word implies that it’s just sucking up to people. Which, I mean… it is… But that non-judgmental cheerleading, agreement, and yes-man’ing has been helpful at least to some. Not all of us are masochistic ex-Bridgewater robots or (as one business school professor derided me as in a heated debate) Vulcans.
And this is partly why OpenAI is bringing 4o back for paid users soon, at least for now. It’s a bit surprising they didn’t expect this reaction, though. I personally wouldn’t mind still having access to some of the extremely fast mini models. Not all tasks require embedding a ton of world knowledge.
Other parts of the rollout were perplexing too—I did a double-take on some of the announcement stream’s charts. For OpenAI’s long-delayed, much-anticipated release, it all seemed quite sloppy.
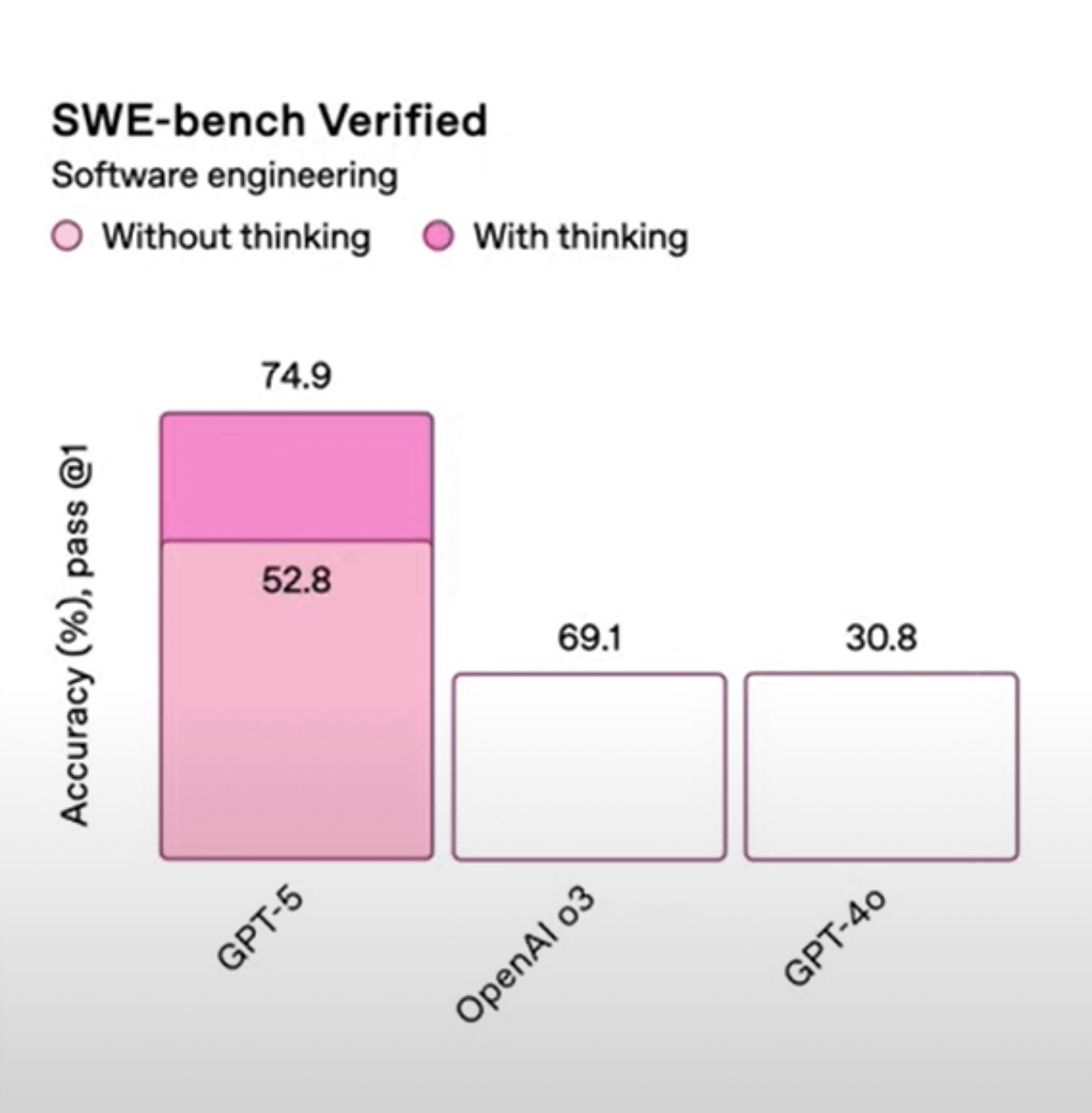
Putting that aside, forward progress is continuing. Despite how it feels now, that wasn’t a foregone conclusion. It was the end of last year (eight months ago) that the media was feverishly asking whether or not AI scaling was over. It’s obviously not.
From the other extreme, though, I also think it’s reasonably clear that we aren’t suddenly going to wake up to either Judgment Day like in Terminator 2 or AI suddenly becoming superintelligent.
As usual, Nathan Lambert has an interesting take, and I like his synthesis here:
If AGI was a real goal, the main factor on progress would be raw performance. GPT-5 shows that AI is on a somewhat more traditional technological path, where there isn’t one key factor, it is a mix of performance, price, product, and everything in between.
Given all of this, where does this leave our vision of the future?
Peering into the Crystal Ball
My upcoming book, What You Need to Know About AI, will be coming out in October (!!), and I had to ponder some of these questions. The book isn’t meant to speculate about the future. It’s a “survey class” of AI’s history, technical underpinnings, business fundamentals, and how it’s being used today.
Still, some of my concluding chapters grapple with its impact on certain jobs and the nature of creativity (and “humanness”). It’s hard to avoid it and a bit of a disservice to readers if I just dropped them off abruptly without addressing why people care so much about AI to have read an entire book on the topic.
These aren’t directly from the book but more just thoughts based on what I’ve seen in online conversations about AI. These are my own opinions and synthesis—which is all it can be, since no one knows the true answer to these yet.
1. We aren’t going to be become drooling degenerates hooked on AI
Calculators were once supposed to make students dumb, because no one would be able to do math anymore. I still remember when I was in high school that teachers tried to police the use of the TI-89 (originally released in 1998, but there was a re-release of the “Titanium” version in 2004). It could solve algebra problems and even store programs/macros. The idea was this overly powerful calculator—if allowed in classrooms—was going to make our kids completely unable to learn math.
That’s almost laughable, of course, in today’s world with Wolfram Alpha and, you know, ChatGPT.

Each generation of technology has generated this kind of moral panic. The most recent one is that AI will turn us into mental degenerates who can’t flex our brains at all without consulting an LLM.
Is it useful to be able to do fast mental math? As a former hedge fund person and now as someone in charge of a lot of workstreams where I need to at least be able to know if certain stats and figures are roughly right… yeah.
It’s also great as a parlor trick too. Impress your friends by knowing the answer to some calculation by just sitting there while they look it up. I personally suggest Secrets of Mental Math, which was super useful to me when I was younger.
However, do I think someone is truly stunted by pulling up the calculator app on a smartphone? No.
Similarly, is there a fundamental value in using traditional Google search over ChatGPT? Was there one in using an encyclopedia over Google? Was there one in memorizing oral traditions over the written word?
We’ve used tools to make our lives easier throughout all of human history. Hell, even LLMs themselves use tools nowadays. There’s nothing brain-melting about using AI to now look up, calculate, summarize, or otherwise do things that require relatively little mental rigor—but do take time.
Also, having been around a lot of successful people of means (read: rich), many of them use assistants, leveragers, or other kinds of people around them to do things for them. It didn’t stunt their intellectual ability. If anything, it usually freed them up to do what they’re really good at. Now, far more people who can’t hire armies of assistants have the ability to capture a lot of the same kind of value.
2. The kids will be all right… eventually
I’ve had interesting debates with a lot of smart people about the future of work—specifically, the future of work for young people today.
I started out being pretty dismissive about AI being a threat to young people’s jobs. The economy has adapted to all sorts of things—and young people, at the beginning of their careers, have plenty of fluidity to adapt.
But, over time, as I noticed that AI was massively more valuable for experienced experts, heard multiple entrepreneurs say they simply didn’t hire for far longer, and noticed myself that I could get a ton of stuff done with LLMs for coding, data entry, and similar tasks that I would have otherwise gotten interns to do… I changed my mind.
The “missing link” for LLMs and similar deep learning algorithms is that they have no inherent motive drive on their own and don’t have “creativity.” That’s a fraught topic about what that even is—but deep learning algorithms inherently learn from distributions and draw from them.
Debating with those who say that there is no true originality in the world and everything is fundamentally derivative (there is no original art, novels, etc.) is like debating with someone about the world being a simulation. It doesn’t seem right, it gets tiring quickly, and ultimately it’s more of a religious stance that means we’ll have to agree to disagree.
Regardless, I’ll assert there is some level of creativity. These models will always have trouble exhibiting it by their very nature. As per Logan Thorneloe here:
I’m also intrigued by how many people are surprised by the fact that models can’t perform outside of their dataset when by definition this is how deep learning works. The real way to get them to generalize further is by finding unique ways to expose to more data.
Do you know what general population often has relatively little independence/motive drive and (useful) creativity? New graduates and entry-level folks. There are exceptions, of course. One of the biggest pushbacks I’ve had are from tech founders of currently tiny companies who talk about how incredible the young people they hired are. I’ve had remarkable interns myself who are better than experienced hires. That’s rare, though, and a cherry-picking of the 0.001%.
Generally, young humans often need a bit more experience and time to really take off. What happens if they don’t get those opportunities, though?
This is happening a lot in software right now.
Addy Osmani wrote a piece some time back called, “AI Won't Kill Junior Devs - But Your Hiring Strategy Might” arguing that junior engineers should now learn higher-level skills and warns that:
Despite doomsaying that AI will kill off entry-level programming jobs, the need for junior engineers isn't going away. Industry leaders have realized that completely bypassing the junior level is shortsighted – after all, every senior engineer once started as a junior. As Camille Fournier bluntly put it, many tech managers who shifted to "senior-only" hiring are asking for trouble: "How do people ever become 'senior engineers' if they don't start out as junior ones?"
I agree, but who will shoulder the cost of that? There’s a bit of a prisoner’s dilemma here, where maybe the industry is better off if we all train new juniors… but everyone gets to take advantage of hiring the trained-up juniors after some other company spends the money to train them.
Big companies like Google may have reason to do so (where Addy works) but few others do—and even Google has to care about its bottom line.
I do think the industry and young people will adapt. It used to be the case that architecture as a discipline had entry-level apprentices largely do drafting. Not glamorous, but needed. Eventually, CAD made a lot of that need go away—and specialized drafters are now experienced technicians who are very fast at using those tools.
Junior architects still do some CAD or BIM modeling today. There is also a ton of other grunt work to do—especially in the regulated construction industry. I’m not quite sure what a junior developer would do that’s the equivalent. Fill out forms for submitting an app to the Google Play Store? However, the industry did adapt, and I expect we’ll eventually adapt to the new normal as well.
But there is likely going to be a transition period. I remember how painful it was getting jobs as a young person—where every entry-level job needed 5-10 years of experience. It’s likely even worse today.
The kids will be all right, eventually... but there might be a lot of dislocation in the meantime.
3. AGI isn’t coming anytime soon
I’m not going to harp on this one as much. No matter how good LLMs get, they are still a categorically different thing than human intelligence. DeepMind and OpenAI can win more Math Olympiads, LLMs can keep knocking out successive ARC-AGI tests up to ARC-AGI-50 or whatever, but knocking over setpiece benchmarks is not the same as human-level intelligence.
As per Logan’s quote above: the real way to make a model more capable is to give it more data that is currently out of sample. We can keep doing that and make these models broader… but it still doesn’t look like human reasoning or problem-solving.
There’s fascinating philosophical thought experiments like John Searle’s Chinese Room, or frameworks like Judea Pearl’s Ladder of Casusation.
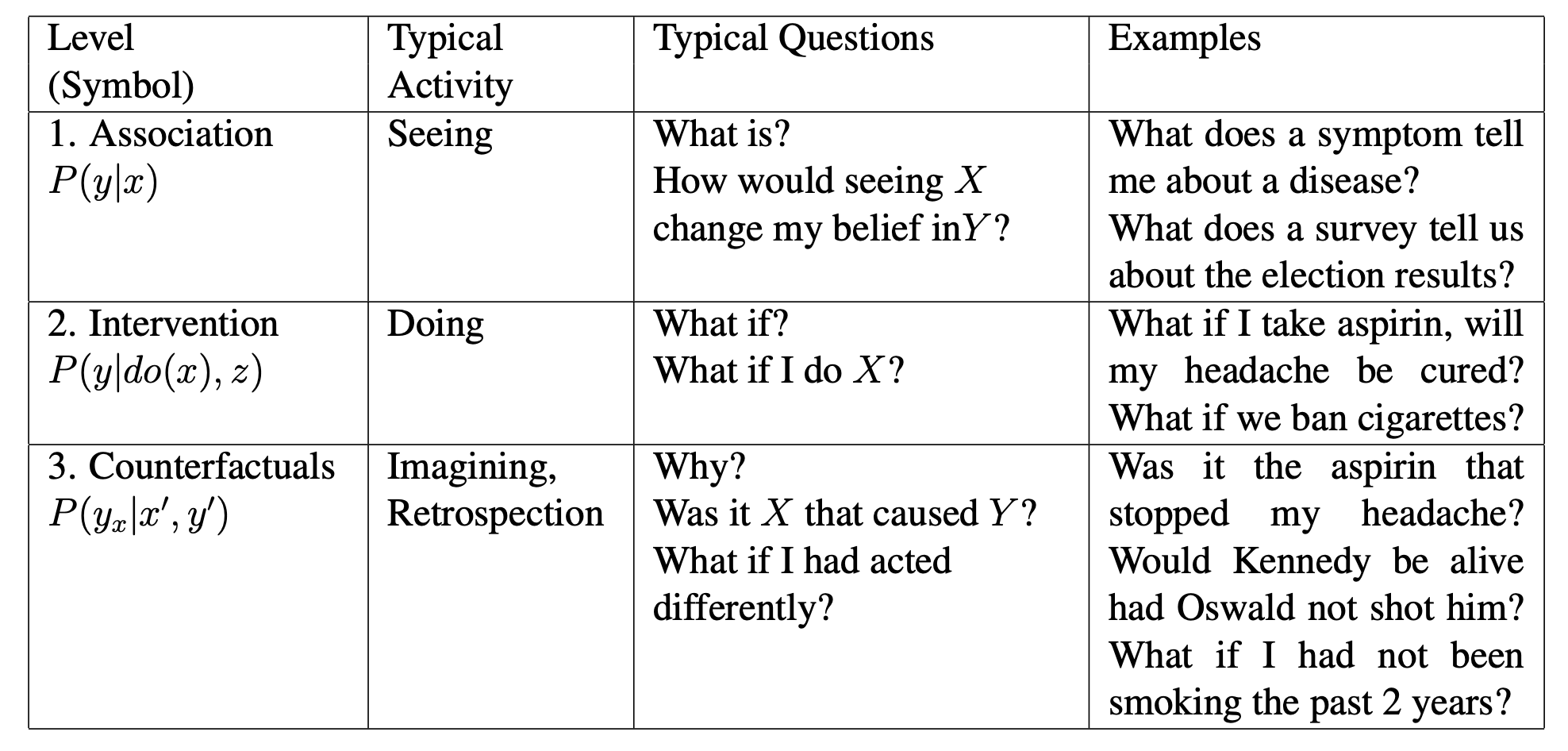
Each can be the subject of their own posts.
However, I don’t think it’s particularly controversial now that AGI isn’t lurking literally around the corner, ready to impact Alphabet or Meta’s next quarterly results.
That doesn’t mean I don’t think AGI won’t ever be reached. I think it will. I’m not saying that I think it’s unachievable in my lifetime. It might very well be within it. I’m not even saying it isn’t within ten years. A lot can happen in ten years.
We don’t have a clear way of getting there and nothing right now seems to be that promising. I would assert (being in the “deep tech industry”) that it’s in a similar place as general quantum computing. There are theories. Some are probably good theories. But there are no practical, testable solutions that gets us there today.
That means it’s very, very unlikely to suddenly burst onto the scene in three years, or even five though. And once we reach five, we’ll have to reassess again—and it could very well be another “five years and then we’ll reassess.”
The same applies for AGI.
LLMs may feel magical, but it’s important to understand their fundamental limitations. That doesn’t mean they aren’t useful. They are obviously very useful for a lot of applications. But just being useful doesn’t make one human or human-like in intelligence.
Thanks for reading!
I hope you enjoyed this article. If you’d like to learn more about AI’s past, present, and future in an easy to understand way, I’m working on a book titled What You Need to Know About AI that will be published October 15th.
You can learn more about it and pre-order on Amazon, Barnes and Noble, or Bookshop (indie booksellers).

Great article! Im happy to see now that the overwhelm of "AI is the greatest, it will solve all the worlds problems in less than three years" are giving way to more sober looks at it.
It says to me that one of the questions many asked is will AI follow the Gartner Hype Cycle. It's clear that's where are headed, probably just coming off the peak of the hype cycle headed in the trough, where we will likely see many of the instant millionaires lose all their money and many startups crash and burn. Enshitification is already starting, see ChatGPT5's forced model selection.
As for the magic. I dont even feel like AI is the biggest innovation in tech. I'd argue, the computer im writing to you on, that is posting this data to the internet is still by far the biggest innovation. It didnt cost jobs overall, after the initial hit, it added so many more jobs. Thats my guess of why AI will do. Possibly a dip in jobs for a bit as we adjust, but then with more comes more. That rule has always held true.
So... I loved my Texas instruments 99/4a. Parsec. Basic. Analog audio cassette backup. If you write software and don't know about these systems that trained the people that will help solve the AI cluster fux. There are so many. Time to go back to remedial computer school. If you have never built a Java compiler with complex memory management. Remedial School. Don't know what zero trust means. Step away from your chat bot. Soc-2. Just leave the conversation. Can't believe I'm writing this. But silicon valley be stupid these days. Time for remedial School. My 2cs.