

Knowledge Agents: Beat Frontier Models with Better Structure
No Mythos, No Problem


Anthropic recently had to pull Mythos/Fable due to an edict from the US government. While Mythos was a step up from Opus, I’ve been actively moving smaller in terms of my agentic models—and matching the quality of output of some of the largest frontier models.
The use cases have spanned from hard “hedge fund level” (for want of a better description) market analysis, financial management, and AI personal assistants to even helping a few friends in difficult medical situations. I’ve called this pattern “knowledge agents” with a generic template available to everyone here. They literally inject the right knowledge into the AI agent plugged into it. Anyone can do this, with or without my template.
As my README proudly declares (yes, I absolutely do have AI write my documentation—do you like writing comprehensive technical documentation?):
This methodology was developed and battle-tested on a markets knowledge agent, meant to replicate James Wang’s thought process in markets: ~10,000 pages of scanned financial market reference materials + ~100 web articles, producing 381 concept documents and 54 thesis documents with hybrid BM25 + semantic search. This was further tested on other specialized knowledge areas—including company-specific policy docs (for a “corporate knowledge agent”) and rare research areas (women’s sexual health, given James’s background)—to great effect. The generalized version here captures a domain-agnostic methodology so it can be applied to any subject.
These were the first, but at this point I have twelve of these specialist “knowledge agents” that handle queries from other agents. Or, obviously, from me. When I’m coding new things that require specialist knowledge, I often start Claude Code in a knowledge agent folder instead of making a new folder and have it benefit from the expert knowledge within it to plan. Especially for specialized machine learning algorithms or economic models, I get far better results this way than with a “subject-agnostic” model—even a really big frontier model.
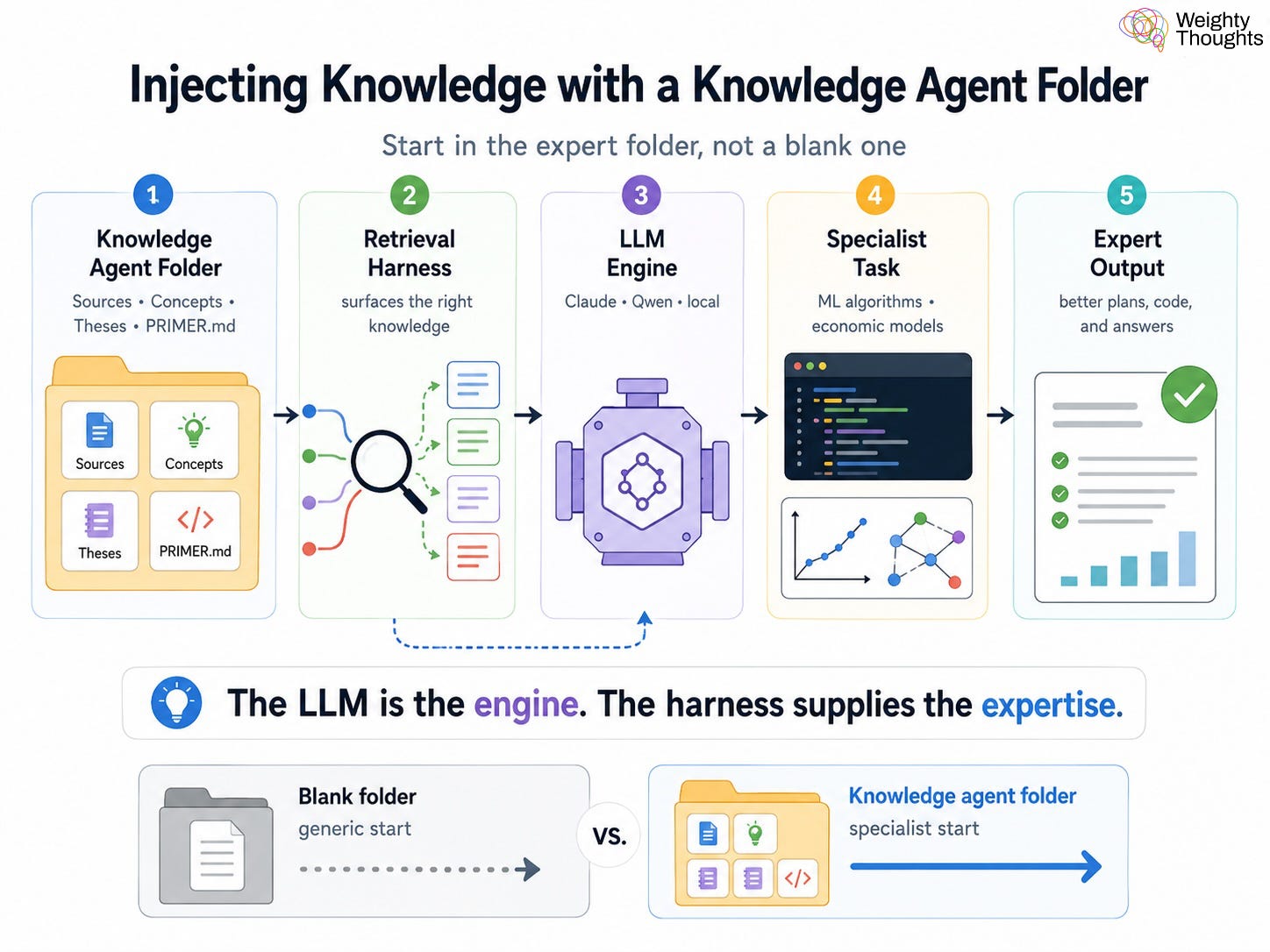
In general, I have used Claude Opus in these knowledge agent “harnesses” (one way to describe this “superstructure” around the AI). As such, it’s pairing the really big model with injected knowledge from the harness. However, I’ve found that I get very, very good results even with far smaller models. The LLM is merely the “engine”—all of the expert knowledge is provided from my knowledge agent system, which surfaces the relevant knowledge at the right time.
Relevant, of course, is key. As most of you know, you can’t just drag 10,000 pages of documents into your chat window. Even if you could, you’d get a mess of irrelevant information drowning the LLM. In practicality, you’ll probably run out of context and never get an answer if the platform even lets you do it.
This has allowed me to move many of my agents from Anthropic’s Claude (ahead of a billing change that would have cost me $2k+ per month that now got delayed) to a locally run open-weight Qwen model. It’s a tiny fraction of the size of Claude Opus (the flagship model) and is able to run on hardware I have plugged in at home. It’s next to my feet right now as I’m typing.
(As a random note, you do have to point your non-Claude agent at CLAUDE.md or copy it into AGENTS.md—AGENTS.md is often the convention for non-Claude systems as the equivalent “agent needs to read these instructions first”)

How does it work?
The simple answer, as said, is that it injects the right, specific knowledge into the AI agent at the right time. The longer answer? Let’s first talk about the forms that knowledge takes in LLMs.
First, a significant portion of frontier models’ huge footprint is “knowledge.” I might call it pseudo-knowledge, since it’s probabilistic and there’s no guarantee it’ll give you the right answer... but the biggest models have been trained on an enormously broad set of data. This is captured in numerical weights as “parametric” knowledge. While that’s very useful if you’re casually asking Claude Opus or GPT-5.5 about some random topic, it’s entirely irrelevant if you either already have the data you want to reference or the data isn’t publicly available anyway—so it could never train on it. The latter is quite common in fields that are specialist (areas of medical research), secretive (high finance), or proprietary (frontier, company-specific materials science). If I don’t need it... well, a lot of the massive size of the model to cover every random subject matter is a huge waste.
The second form is data provided in the context window—in other words, your prompt/query. That data is not the same as weight-driven “knowledge.” Injected knowledge in the context window (refresher on that if needed) does not make it impossible to have hallucinations, but it is mechanistically different from parametric knowledge. And, in general, if you’re injecting relevant knowledge (in theory, a good system should do that vs. irrelevant knowledge) it’s right there and more likely to be used. While not impossible, you generally don’t get hallucinations when you ask a modern frontier model to summarize text that you literally paste into it.
And, again, in the case of knowledge that is either absent or rare in parametric knowledge that LLMs ate from the broader internet, you are required to give it the knowledge in order to get a good answer.
This base concept is RAG (retrieval-augmented generation). For less technical folks, it’s basically a fancy way of saying you pasted in a bunch of relevant data/context in your query.
This seems kind of obvious, but the difficulty is not “give relevant information.” It’s how to actually do it and surface the right thing for a good answer—even with extremely difficult questions. This is actually an area of pretty serious academic research. My particular homebrew solution may not be the absolute best, but it works very well—beating a lot of the off-the-shelf libraries for the topic areas I’m interested in, which usually involve a lot of extremely difficult, proprietary knowledge that spans a ton of sources (e.g., finance/trading, esoteric areas of medicine).
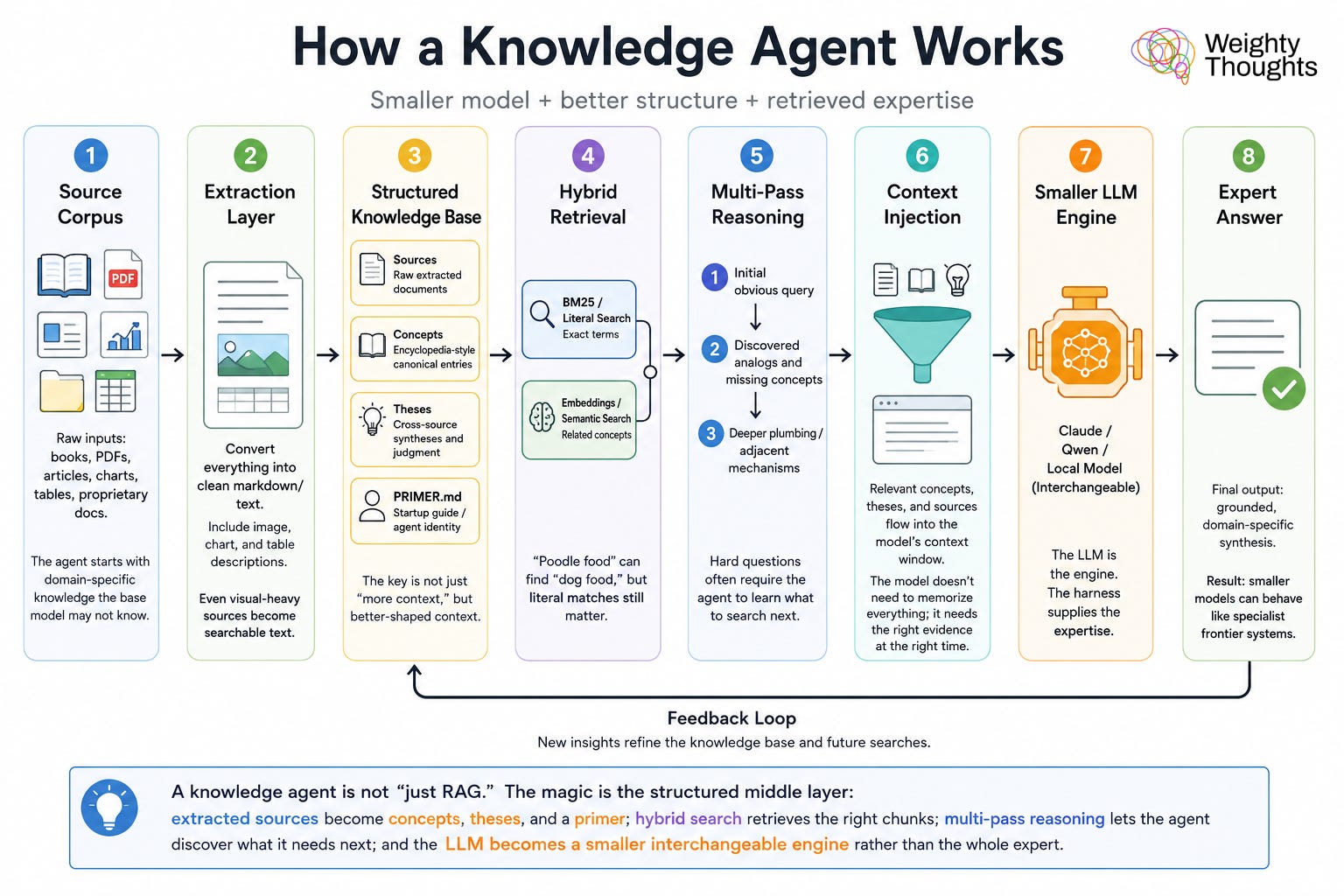
Embedding
The first of these other aspects is embedding. A naive text search is going to often miss things. If I search up a concept about a “poodle,” things that relate to “dog” might be highly relevant. It would be a terrible system if searching “poodle food” brings up nothing even with oodles of information about “dog food.”
This has been a part of natural language processing for years, but the concept obviously has relevance to LLMs (large language models) as well. One of the layers of transformation of words (well, tokens) into numerical representations is what those words, or word parts, are related to. That’s the job of the embedding model.
To not be awful, we need to have, at minimum, base-level related concepts come up that don’t need literal matches. In my knowledge agents, I use both literal search and search using embeddings.
For calculating embeddings, I now use a local embedding model (BGE-M3), but OpenAI has an easy one to use with just an API key (text-embedding-3-small). It’s cheap enough that I think even with extraordinarily heavy use—and you only need to run the embedding model with new knowledge added—it’d be a herculean effort to ever exceed the cost of a Starbucks coffee.
In all my time using it, processing thousands of documents, before I switched to an embedding model on my own machine... it cost me less than a dollar. If you use my template, put your OpenAI API key into .env.example and remove “.example”.
Structure
While it’d be nice to just have a search (enhanced by embedding) give me exactly what I need, how much is actually needed? If a search merely brings up the sentence it’s in... well, that might not be enough. We’d at least need the surrounding sentences, right? But what if the surrounding sentences aren’t enough and we actually need the entire, say, academic paper? It’s often hard to say.
In that case, why don’t we just bring up the entire paper? Well, this becomes an issue if we find a lot of papers. It’s an even bigger one if stuff is just really long. In some of my knowledge agents, I’ve fed them entire books (including my own, for one that is basically a knowledge agent that brings up anything I’ve written—or... and no, I haven’t done this with any readers... answer questions as me based on what I’ve said before). An entire book is way too long to be a reasonable search result to return.
The question here is how do we chunk our data? Yes, that is the technical term. How do we break it up into (as it sounds like) chunks that are relevant?
This is actually quite hard and took me a lot of trial and error. For my purposes, having referenced summarized subdocuments for certain purposes ended up working. I have three types of documents. Well, four if you include the actual sources:
Source extractions—these are the raw sources in markdown. One of the costliest (in tokens) parts of my workflow is that I have a model in the harness describe in detail what’s in images and charts. As such, we work with “raw” files that are pure text, even when they started out image-, chart-, or table-heavy.
Concepts—these are the “encyclopedia entries” for our canonical knowledge base. We need grounding concepts... and these are it.
Theses—these are more opinionated, cross-cutting syntheses of multiple sources. If certain themes emerge, we should capture them in theses.
PRIMER.md—this is the “summary” and self-updating guide that helps orient the agent on startup. Remember, AI agents start with no memory—so this gives them at least a basis for what kind of expert they are (with knowledge retrieval) within this knowledge agent harness.
This extraction process and structure is key and I’m not going to lie—it’s extraordinarily costly in tokens. Every time you add new data, you may need to add new references in concepts and have more theses. Sources can be heavy token hogs if they have a lot of images/charts. But cross-cutting concepts and theses are even more.
Computer science and statistics majors would understand. This is a combinatorics problem. Each individual document needs to be referenced against all the other documents (at least in theory) by the AI model running the process. This blows up combinatorially and gets ridiculously costly, fast. But it’s also key to giving you the right chunks when you search, especially with the next step.
Multi-Pass, if Necessary
While this particular step isn’t as costly as knowledge extraction, I have indeed found that to get the best results, we need to set even more tokens on fire. Even with perfect concept and thesis extraction, sometimes we have a really, really hard topic that requires multiple searches. While the knowledge agent always has the option of reading sources, sometimes you need a completely different search.
Why? Let’s bring up an example. If I have a totally insane query, say, “Describe the Bank of Thailand’s balance sheet during the Asian Financial Crisis and tell me what lessons or transferable ideas there are for the US today.”
What should the agent search? Well, obviously “Bank of Thailand” and “Asian Financial Crisis.” But US? Too broad a search. A smart enough model (so, no, you can’t throw one of OpenAI’s mini models or Claude Haiku at this thing) would realize from the first search that “Bank of Thailand” is the central bank of Thailand. The analog in the US is the Federal Reserve. Also, Thailand uses the Thai Baht, but the Asian Financial Crisis was also a currency crisis, so an analog would need to be USD.
Ok, we already have a second level of searches. But as the agent reads more... it realizes it actually needs to understand how being the reserve currency (USD) makes a difference. And also better understand the underlying financial plumbing of the Fed system, how money markets, etc. work... and bonus points for recent events in terms of gold accumulation by central banks as a recent topic.
Regardless of if any of that made sense to you, I designed it as a question that cannot be answered well without a lot of deep knowledge. That, after all, is the point of a knowledge agent. If I just needed to get a summary with easy queries... well, any basic search would do it.
The concept here, which is written into the instructions for the agent, is it must do multiple passes. How many? Well... this is where I did an empirical kludge. Without pre-knowledge, the agent has no idea how many searches are appropriate. One is too few. Ten could start to pull in the whole knowledge base. I landed on three. In general, that gives enough breadth without drowning the agent. Four or five is likely fine, but I kept it to the minimum where I could see generally good results.
Easy queries (e.g., “What is the Bank of Thailand?”) need to short-circuit this though—which also needs to be an AI agent “gametime call,” which I don’t love, but is written in the instructions. While the results of multi-pass aren’t always horrible for easy queries, multi-pass does dump a lot of extraneous information in and tends to make easy questions really wordy and meandering.
So how well does this work?
Well, see the results for yourself. There is a nuance here that you should notice, however.
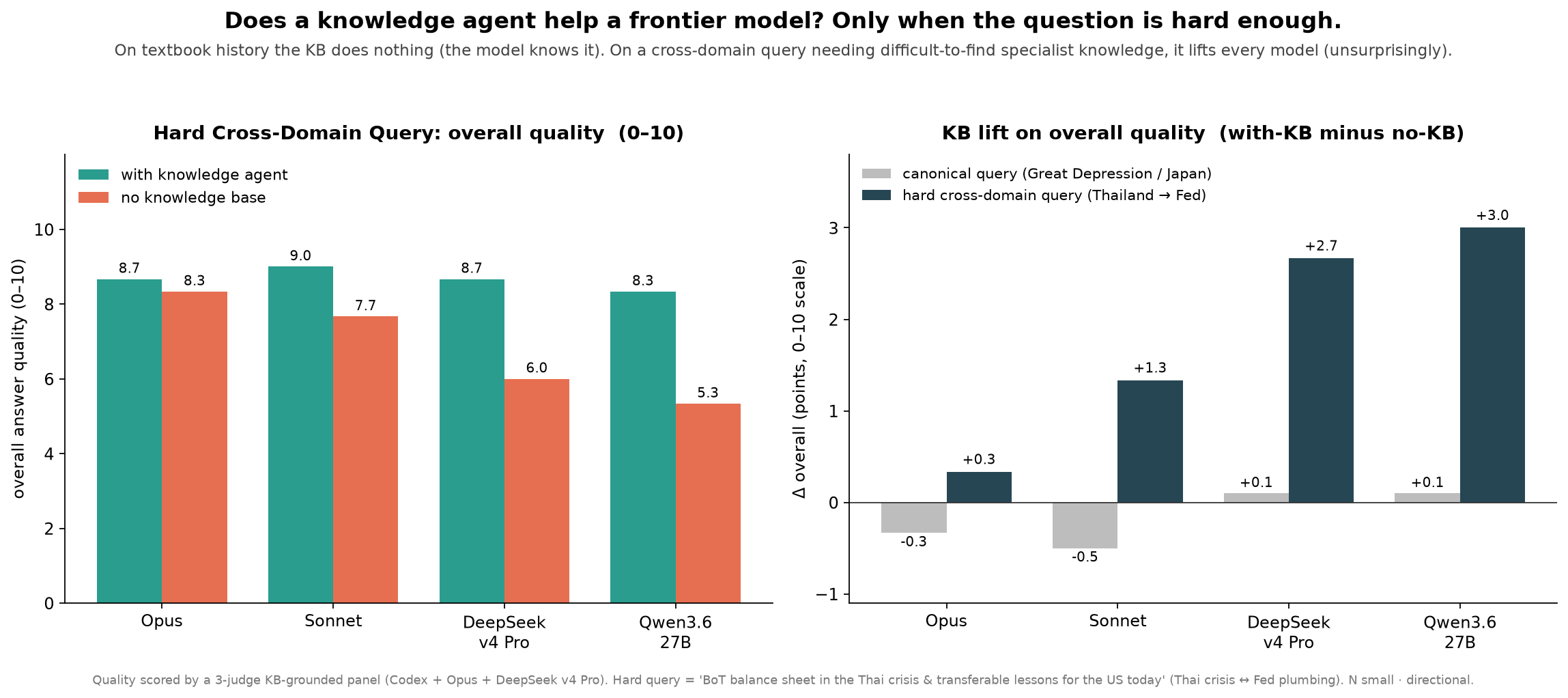
I threw a fairly simple (well, as far as it goes) question about lessons from the Great Depression and Japan for monetary policy. These are simple topics that I could probably ramble on about half-asleep. Regardless, they’re definitely in Claude Opus and similarly sized models (like the recent DeepSeek v4 Pro).
Actually, seriously, if you’re curious about the topics, I suggest Lords of Finance and The Holy Grail of Macroeconomics. Liaquat Ahamed, author of Lords of Finance, was also slated to be a speaker at the recent Sonoma Valley Authors Festival—I was super disappointed he didn’t make it and sign one of my favorite books from when I was young! Speaking of, if you want to hear my talk during the Festival, it’s now online here! https://svauthorsfest.org/virtual-festival/
My Bank of Thailand related to the US query? It’s the kind of question I’d torture young, new analysts with because I believe pain is the best teacher, it’s kind to be a good teacher, and I’m a kind person. None of the information is secret or proprietary... but it is definitely hard to pull together the pieces.
In a way, our results do tell a story as to why Anthropic is riding high right now. For such a hard (stupid) query that I would expect even a good human analyst would find somewhat annoying/difficult to give a coherent answer to, Claude Opus 4.8 did remarkably well. As you can see on the righthand chart, the knowledge agent basically didn’t really help it. In fact, on the easy query, the knowledge agent actually hurt it, probably because its built-in parametric knowledge gave more relevant information.
Even Sonnet (Anthropic’s “everyday” version of Claude vs. Opus for the “hardest problems”) did well, despite me comparing it unfavorably to Qwen 3.6 27B in my last article. Perhaps the biggest disappointment for me was how poorly DeepSeek v4 Pro did—since it’s meant to be broadly in the same weight class as Claude Opus.
Nevertheless, the real story is less how they each did without the knowledge agent harness. It’s how they did with it. The righthand chart gives the story of how much of a lift the harness gave the now empowered “knowledge agents.”
The left shows that the harness basically equalized the models, including Qwen 3.6 27B. Remember, that model is literally small enough to run at home with consumer hardware.
And, before you ask, Sonnet being “numerically” better than Opus on the left with the knowledge agent harness is really more of a tie.
Plugging a real weakness in LLMs—calling back to the 1980s
Those of you who’ve read my book likely know exactly what I’m talking about. Knowledge-based AI (KBAI)—also known as symbolic AI or “good ol’ fashioned AI”—was our prior generation and caused our last AI investment boom in the 1980s. Unlike today’s AI, it never got an answer wrong or hallucinated, because it had a strict process of drawing from a knowledge base and applying rules. If it got something wrong, it was because of either faulty knowledge or poorly written rules.
The “real” work of AI was often referred to back then as “knowledge engineering,” which tells you something. Unfortunately, this approach proved highly inflexible. The real world is quite complex… and it rarely graces us with circumstances similar enough to easily compute through existing knowledge and rules without “remixing” or going beyond what our existing knowledge implies.
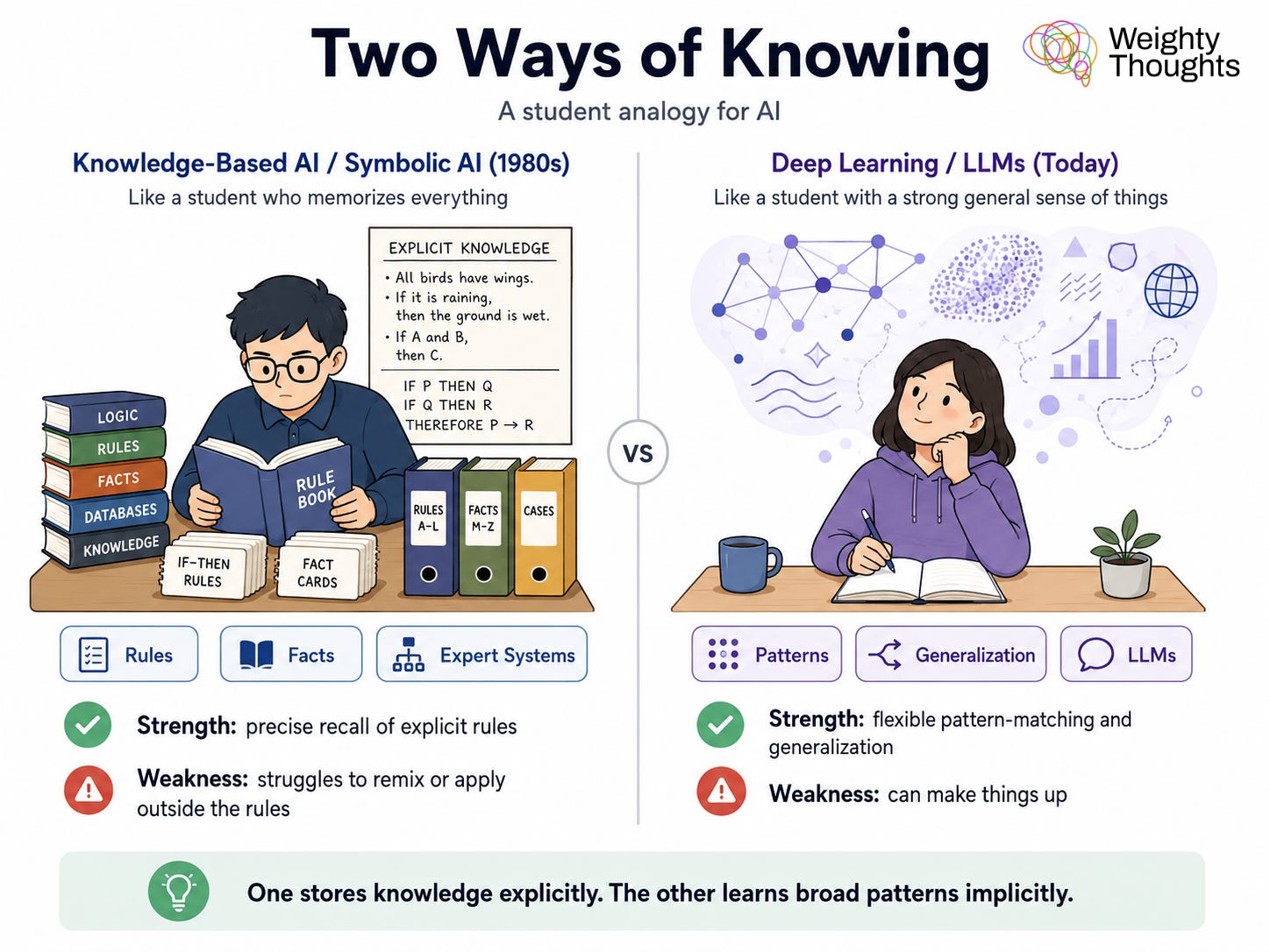
Today’s AI, as I discussed with the “numerical weights” for its parametric knowledge, is much more free. I usually give the analogy of a student who has memorized facts but isn’t able to apply them broadly and another student who really doesn’t remember many facts but is able to “get the gist” (and sometimes makes things up that “feel” right). KBAI is the former, and modern deep learning (especially LLMs) is the latter.
This structure is attempting to plug the hole, because, as I lay out in the book, we can never totally remove hallucinations without destroying the utility of modern AI. It is, in a way, a hybrid system—which is what inspired my naming of them: “knowledge agents.”
This isn’t a story of “Claude is bad”
There have been a spate of people canceling their Anthropic subscriptions due to annoyance about Anthropic’s policy changes or improvements in smaller models. This is not one of those stories.
If Anthropic had never brought up making claude -p (headless Claude Code instances—the main way I use AI agents) charged at API prices instead of still being on the subscription, which, once again, would cost me $2,000 to $3,000 in tokens per month, I would have never looked into this. Even though they’ve delayed the change that was originally scheduled for June 15th, 2026, I still expect they’ll eventually go through with it.
I still use Claude Opus enough to justify a $200 per month subscription, even without these agents. It’s nice to use Claude Code, which is quite ergonomic. It’s nice to have a million-token context window (though I try not to fill it up due to context rot) and never really worry about running out. It’s also nice to not do much setup and just throw certain problems over the wall with less-than-perfect instructions and still expect reasonable results (or at least results with minor problems I can quickly correct). Anthropic shares haven’t been flying around as one of the hottest things ever for no reason.
But it’s still remarkable how far small models have come, especially with software improvements. It’s great that open-weight models have closed the gap a lot more. And it’s liberating to know that even if Anthropic and OpenAI close off access to their models—or, say, a government forces them to close off their models—we can still get similar results, just with more work.
Devansh also demonstrated something similar with a project of his that used what he called “stateful swarms.” More work and a harness of sorts, but substantially better results with “weaker” models.
To some degree, my title is clickbait—at least for the true frontier models like Opus, we’re looking to match. But Sonnet, also a “frontier” model (but not the biggest of the big), we can often match or even beat. Knowledge agents do genuinely, especially in proprietary data cases, vastly enhance any model. If you can freely use infinite Claude Opus tokens... why not? But it obviously gives a bigger lift to smaller ones, even in cases with merely curated knowledge versus truly proprietary knowledge.
If you build something with my knowledge agent template, let me know! I’d love to hear about it. Additionally, if you have any questions, either on the template or building one of these yourself, you know where to find me.
Thanks for reading!
I hope you enjoyed this article. If you’d like to learn more about AI’s past, present, and future in an easy-to-understand way, I’ve published a book titled What You Need to Know About AI.
You can order the book on Amazon, Barnes & Noble, Bookshop, or pick up a copy in-person at a local bookstore.

that’s a beautiful looking PC, good choice, and neat article James. This idea of outfitting tiny agents with good enough scaffolds to work together and get jobs done is interesting to me too
Infographics are helpful! Thank you for including them within your postings. 🙂