

AI's Plummeting Prices Are a Software Story, Not a Hardware One
This has made local, open-weight models a real competitor to the frontier


Why is model inference getting cheaper? How did I drop a soon-to-be $2,000+/month bill for AI agents to next to nothing? And why are local models on commodity hardware potentially “good enough” for most people?
There are two macro trends here that feed directly into each other.
First, AI inference costs, as I’ve mentioned before, have been dropping 70-90% per year. Guido Appenzeller coined the term “LLMflation” through his original observation that costs have “dropped by a factor of 1,000 in three years.” No matter how many times I say it—and however many smart observers point it out—it still shocks most people because AI feels like it’s getting more expensive.
That’s because costs are dropping for the same capacity (same model, same query), and we’re constantly ramping up what we use (bigger model, more expensive query). It’s the same reason why, despite Moore’s Law (which is slower than LLMflation), computers don’t cost $0.00001—we made computers bigger as we went, even as their cost exponentially plummeted.
This, however, is an old story. The interesting part of the piece is what drives this plummeting cost. It’s not (mainly) hardware. It’s software.
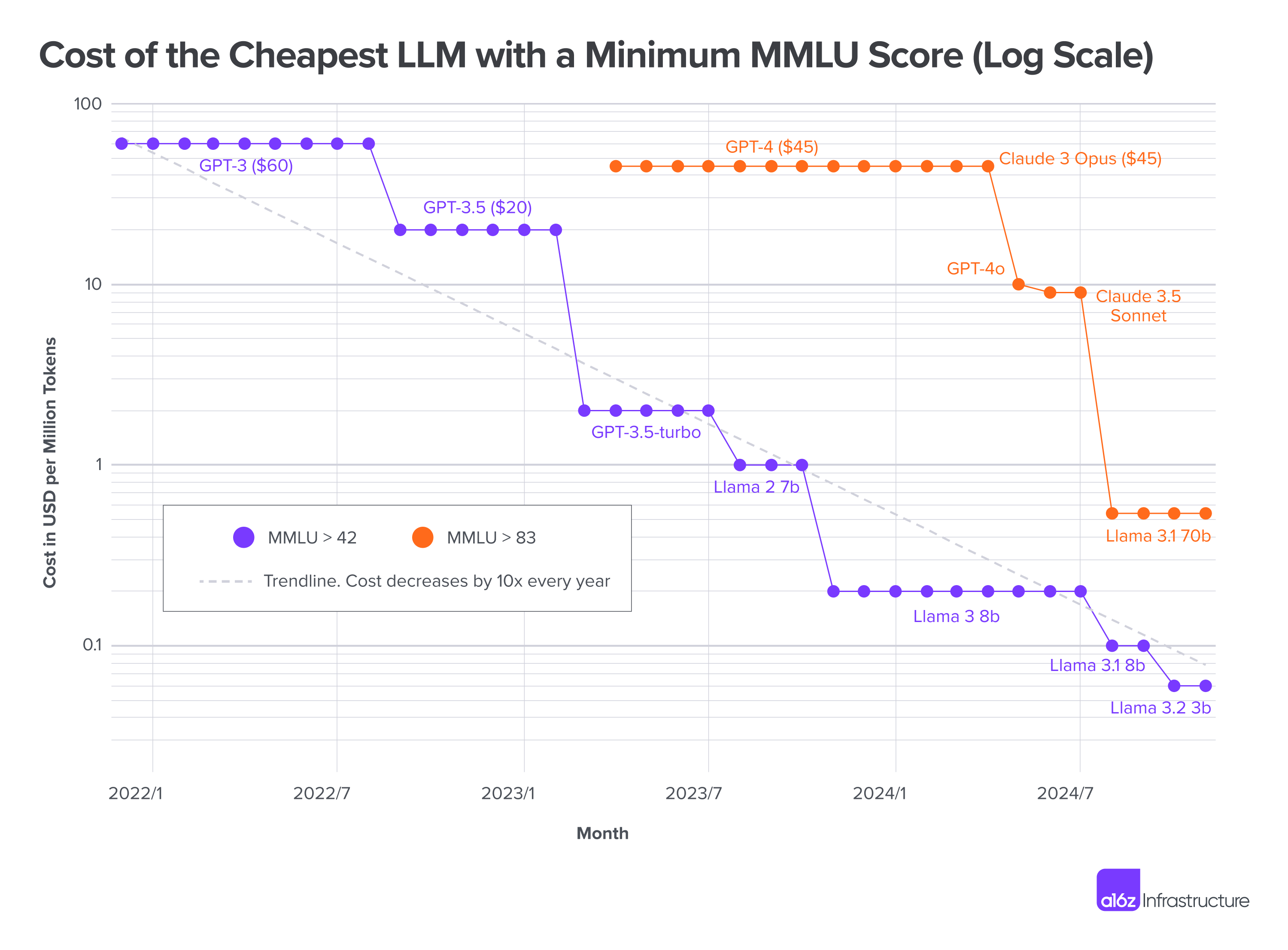
The second is a consequence of that: local, open-weight models on kind-of-old commodity hardware are becoming more and more competitive with models on the frontier. That obviously has big implications—and potential consequences—on what the frontier labs will ultimately be able to charge for the biggest models.
Local AI + Old GPU Beats Frontier Model
I ended up researching and writing this piece accidentally.
I’ve always experimented with open-weight models myself, even when it made no sense to run them. My (public) history playing around with language models goes back to 2014, when I published an implementation of a Google model paper for a data science certification. It’s always largely been a hobby/learning experience with no practical output—until recently.
A few weeks ago, I started playing with Qwen 3.6 27B—released about a month ago in April 2026. I didn’t run it on an Nvidia H100/B200 or some other data center GPU. I ran it on a consumer gaming card, an Nvidia RTX 3090 Ti, released in 2022.
While I heard good reviews of its capabilities, I didn’t expect much of it. To my surprise, it felt like running Claude Sonnet, Anthropic’s model one tier below the biggest model (the one they encourage people to run as their “everyday” model).
Sure, it isn’t Opus (Anthropic’s biggest, priciest model) or GPT-5.5 Pro (OpenAI’s biggest model), but this thing is open-weight/free and runs on a 4-year-old consumer-grade GPU!
Of course, “feelings” don’t mean much for model quality. Fortunately, Anthropic forced my hand on finding alternatives to how I run my rather extensive agent workflow. I detailed that workflow here (it’s still one of my most popular pieces ever). As a note, that was a (relative) eternity ago. I have way more agents running at this point—enough so that I need to actually have agents that manage my agents (I reinvented the org chart…).
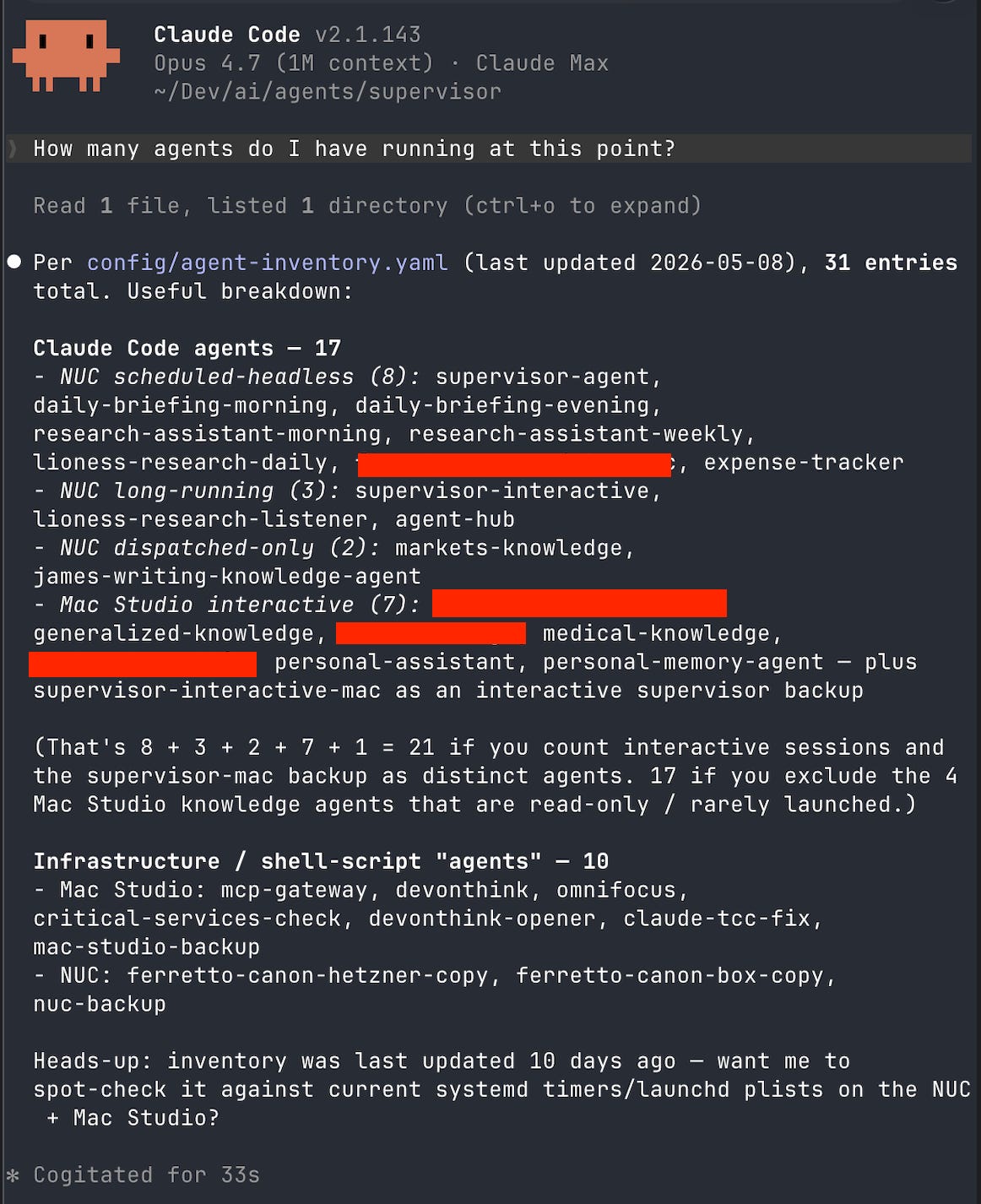
The Coming Anthropic Agent Crackdown
Why did they force my hand? Well, starting June 15, 2026, claude -p—which, as per my agents article, is how most of my autonomous AI agents run—is no longer included in the subscription. Instead, you get $200 worth of credits, which at full API rates is 25x more expensive. So, how much does my agent stack cost? Am I somewhere close to $200?
Uh, no. My automated systems alone would run north of $2,000-$3,000/month at those rates, and the all-in personal number is, well, higher. I do not begrudge Anthropic cracking down on this. I may have been following guidelines from Boris Cherny, head of Claude Code, on acceptable use... but still, that’s a lot of money multiplied across a ton of users.
So an experiment that would otherwise have been “interesting but academic” suddenly had a budget attached to it. Dropping down from Opus to Sonnet for almost everything only got me down to around $1,000/month (and, for some of it, I didn’t get acceptable results from Sonnet).
For part of it, I could use codex exec (OpenAI's equivalent of claude -p) on my $20 ChatGPT plan. Replace one frontier model with another. But $20 isn't enough—especially since I need GPT 5.5 for the harder tasks Sonnet fails at.
The question is, can Qwen 3.6 27B (meaning 27B parameters) really step in for Sonnet (a model that likely has hundreds of billions of parameters)? Well, the public benchmarks seem to suggest it can.
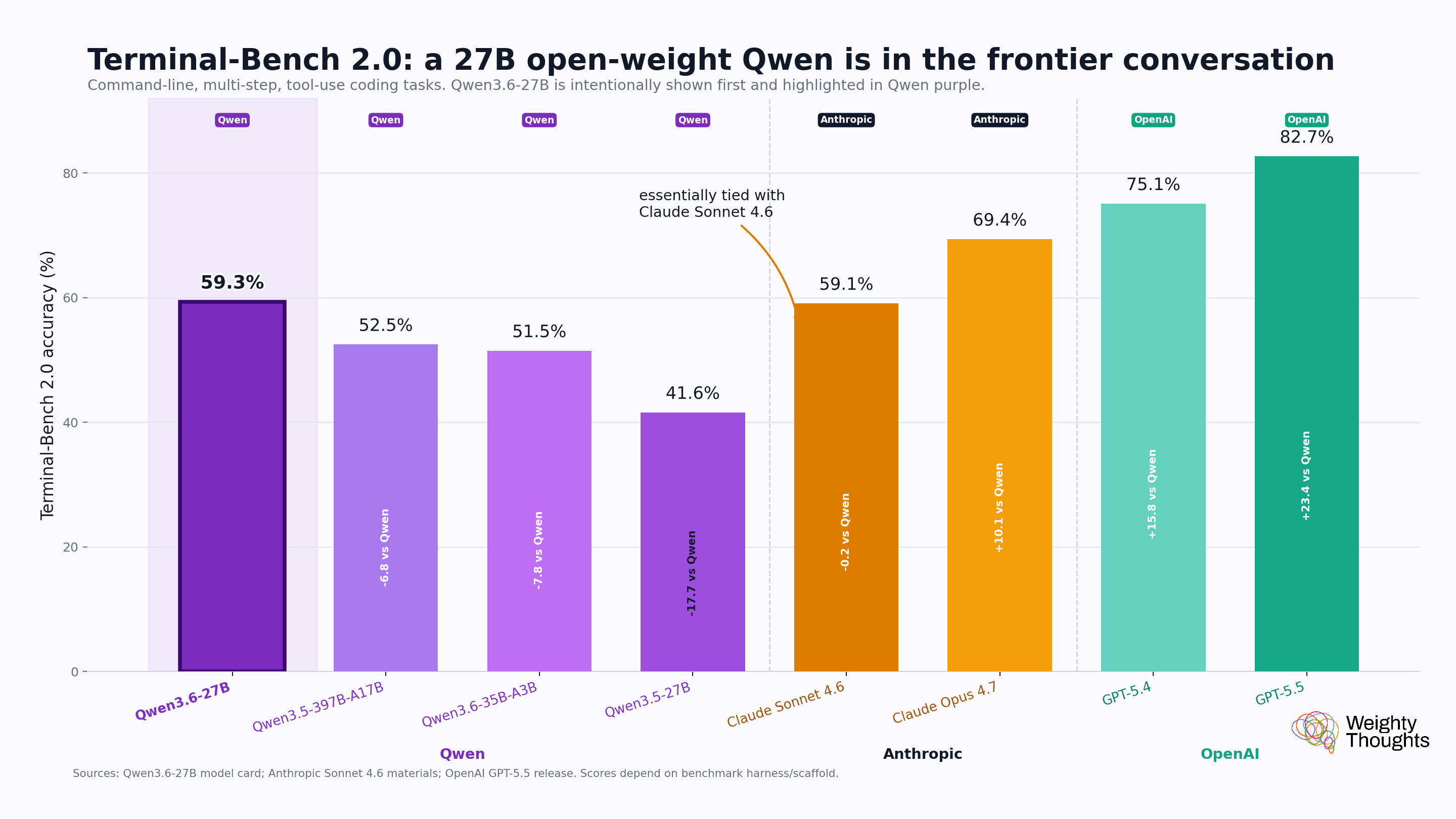
Benchmarks don’t always reflect real performance, however. So I ran a few side-by-side benchmarks on the workloads I cared most about: daily briefing synthesis, chart annotation (especially for various medical applications and AI papers), and arXiv (research paper preprint archive) triage.
Same prompts, same context, four models. For the paper-triage task, “quality” is partly a matter of taste, so I used Opus and Codex as a consensus jury—where they agree on the threshold, that’s the closest proxy I have to ground truth without hand-labeling everything myself.

As a whole, the briefings were largely the same across all of them (so Opus was always overkill; Qwen is fine). Neither Qwen nor Sonnet was good enough for annotation (so I moved it to Codex). Finally, Sonnet was actually worse than Qwen for paper scoring.
This means a 27B-parameter open-weight model, quantized to Q4, on a four-year-old consumer GPU, is doing comparable work to a paid mid-tier cloud API. Yes, it’s not Anthropic’s Opus, but it’s roughly matching Sonnet—a model still very much in Anthropic’s frontier lineup.
Qwen 3.6 27B is a particular standout, and it’s unlikely to beat Sonnet on every workflow. However, it and many recent, “small” open-weight models are at everyday-use quality (not “small language models” but small “large language models”). Heck, Qwen 3.6 27B even has vision capabilities!
While, as per Nathan Lambert, open-weight models have been in “perpetual catch-up” and underappreciated generally, what strikes me is how far down the hardware requirements curve we’ve come for “acceptable” results.
After all of these moves—the scoring workload alone was ~$120/month if done on Sonnet but became $0—I got my projected claude -p budget to under $200/month with a comfortable margin.
(As a note for astute readers, my own power cost is likely not truly $0—especially not being in the Bay Area and having PG&E grace me with some of the most expensive power rates in the country. Still, even with those rates, it’s an order of magnitude less. Definitely less than $0.004 per run.)
The Moving Frontier is “Model”
At one point, an old consumer card like the 3090 Ti couldn’t run anything reasonably competitive with a frontier model. Now, it’s capable of running a model in the same league as a core offering from the top AI lab in the world. My hardware stayed constant—no Santa Claus secretly upgraded my GPU—so obviously something else must have changed.
In August 2023, I wrote a piece called “Compute is Overrated as AI’s Bottleneck,” and the basic argument was that under the Model-Data-Compute framework, the model was doing more of the work than the breathless GPU extrapolations of the day suggested. For me, as per my book, I define “model” as all of the algorithms and techniques that go into making AI work—including post-training, RLHF... but also base improvements in the underlying model architectures themselves.
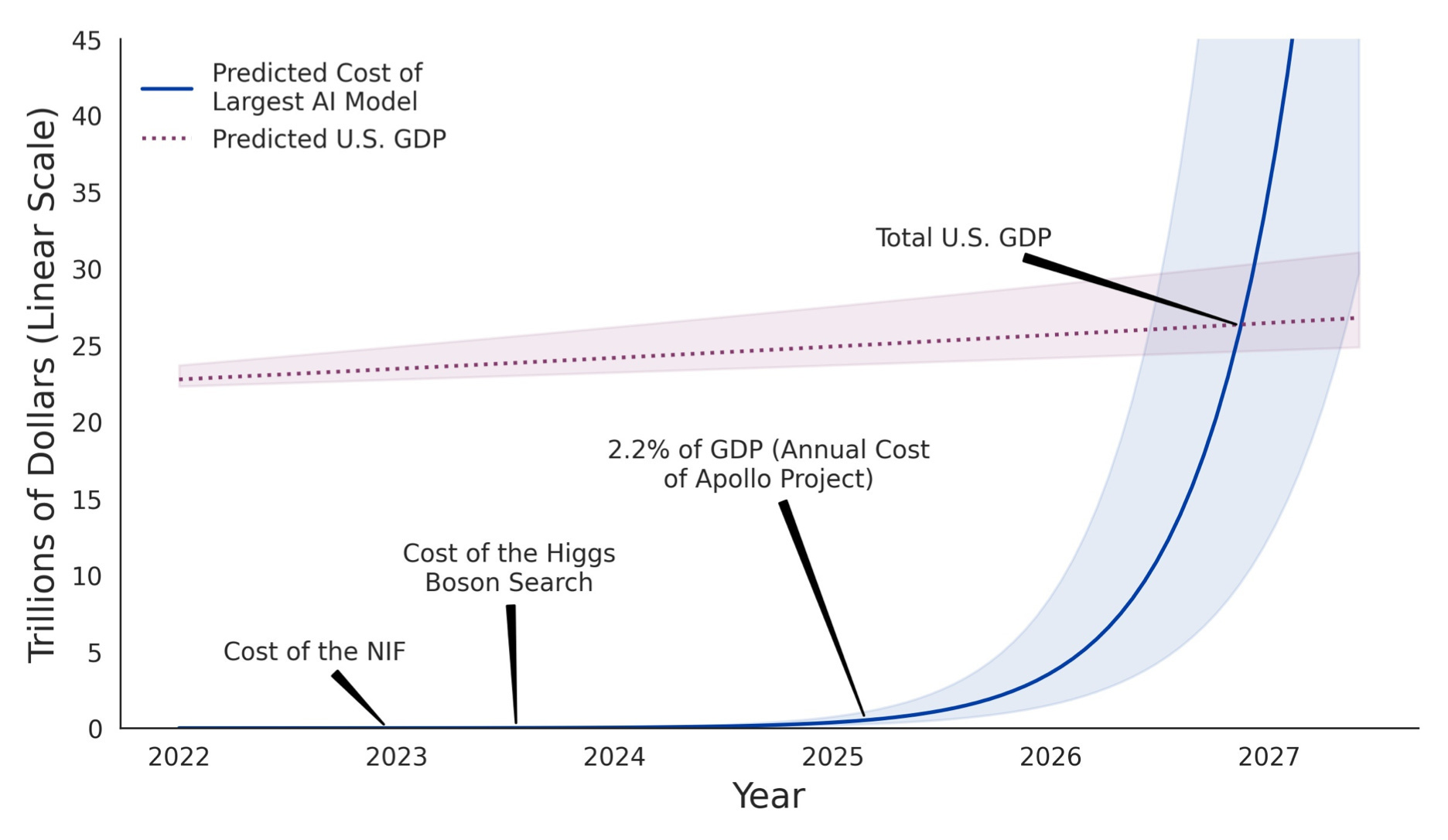
At the time, the prevailing view was that AI training costs would exceed US GDP by 2035 if you just drew the curve forward. My argument—which I'm pleased to say held up—was that “MOAR compute!” mattered less than the architectural and algorithmic gains.
Deep learning (and CNNs, transformers, and more) enabled the current boom, not just “infinite compute”—and new techniques are helping make it cheap enough that anything that can be AI, will be AI.
(Though, as per my book, not everything will be AI… because not everything can be.)
Hardware vs. Software, with Actual Numbers
So, I have a nice anecdote. What does this look like in the broader landscape?
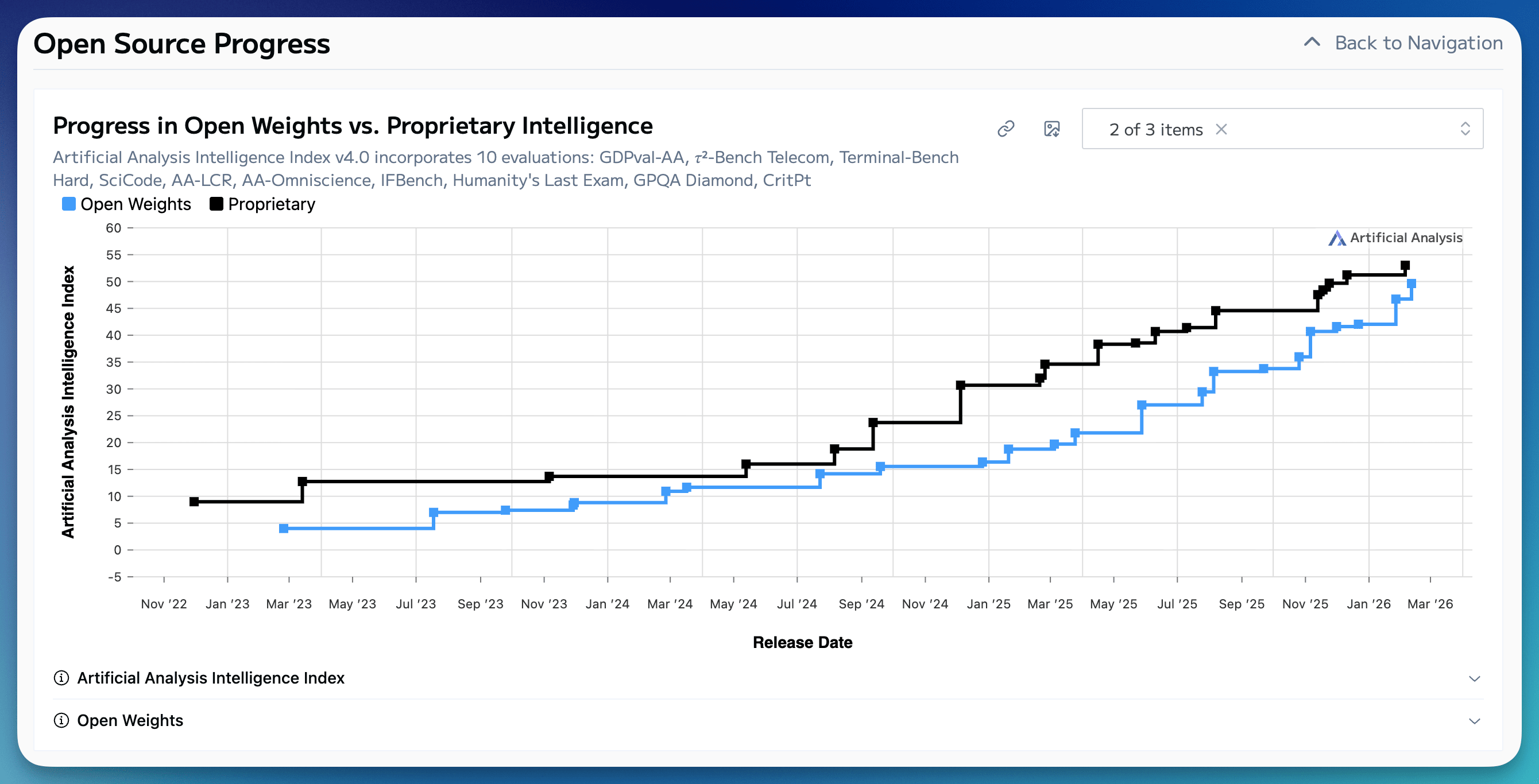
For the recent 2024-2025 window, the best available decompositions suggest that a majority of inference efficiency gains came from non-hardware technical progress—especially model-side or algorithmic improvements—rather than silicon alone. Hardware accounts for roughly one-quarter to one-third, depending on methodology.
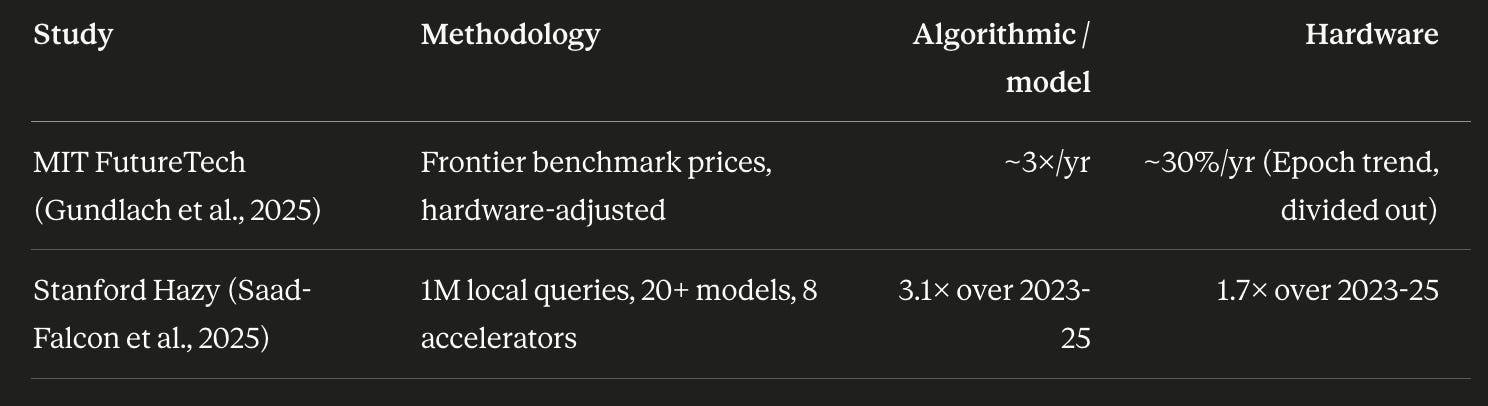
In MIT’s paper, the authors include non-hardware technical improvements, such as data, distillation, MoE, and related efficiency improvements. Stanford mainly focuses on model-side improvements (in local models across consumer/edge hardware).
Regardless of methodology, both reports agree that most of the decline is not silicon.
Perhaps not all of it is literal software, but it is “model” writ large, in the way I use it in Model-Data-Compute (“model” would have been confusing in the title without context, though).
There’s also a useful natural experiment beyond my own hardware.
NVIDIA’s own benchmarks show that H100 throughput on Llama 2 70B improved by roughly 1.5× over a year on identical silicon, from software updates alone. That’s a hardware-generation-sized gain delivered without buying new hardware. H200 added another ~28% on top, and Blackwell another ~3× on top of that—but the same-hardware software work is meaningfully larger than people give it credit for.
On a much smaller scale, the same thing keeps happening to my setup! Software keeps making it better.
While I was working on this piece (literally), a llama.cpp pull request adding multi-token speculative decoding merged and roughly doubled the throughput of my Qwen 3.6 27B on the same 3090 Ti:
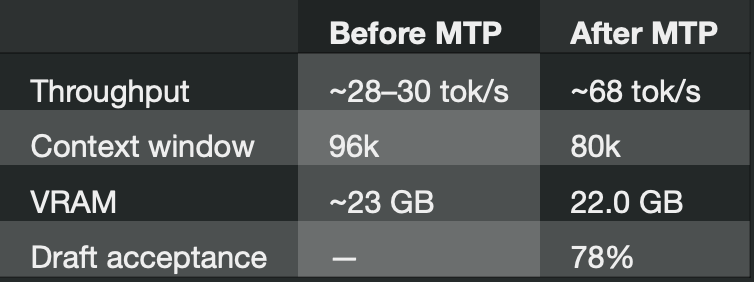
My throughput (speed) basically doubled overnight for free (for nitpickers, yes, I did have to slightly decrease my context window—but it basically makes no difference in practice given the rather marginal change).
Model Improvements, Spotlighted
Software improvements, tricks, and techniques… that’s great and all, but just to be clear, even though we’ve stuck with transformers, there has been a substantial shift in “models.”
Among the notable advances in architecture or formulation have been MoE (Mixture of Experts), which many of the big models have been based on (most famously, DeepSeek v3/R1, which caused the “DeepSeek moment”), distillation (which helps larger models train smaller ones—enabling bigger model breakthroughs to “trickle down” to smaller ones), and quantization.
Quantization is part of what helped Qwen 3.6 27B run on my 3090 Ti—which would barely fit the full size and likely have no context window (read here for a reminder on what that is and why it’s important). However, it has also allowed many hyperscalers and labs, similar to distillation, to bring down the cost of running these models while preserving most of their capacity/performance.
Hardware’s Still Important… Just Not as Much as Most People Think
Of course, hardware is still important. Chinese labs have a thing or two they could tell you about that…
HBM (high-bandwidth memory) on Nvidia’s H200 versus H100—which have the same compute capacity, just more memory bandwidth—gave roughly a 40% “free” inference speedup on memory-bound workloads. That’s pure hardware improvement.
Going from Ampere to Hopper to Blackwell for Nvidia has created significant improvements (that’s why people buy their chips!). Cerebras, an AI chip company, went public last week at a peak of just under $100B (and has since dropped materially...). Groq was purchased by Nvidia late last year for $20B.
These hardware improvements obviously matter. Still, the unspoken consensus is that the main binding constraint of AI is GPUs and chips. As we’ve seen in multiple ways, that’s wrong.
Why This All Matters
In my book, I wrote that “everything that can be AI, will be.” The reason is this cost curve for AI inference.
It’s faster than Moore’s Law, which is what got us from giant mainframes in 1980 to smartphones in our pockets, which are a million times more powerful than those room-sized machines.
Epoch AI estimates frontier capability is now runnable on a single top-end consumer GPU within 6-12 months of being released at the frontier. That’s more or less what I saw (and was surprised by) when I ran Qwen 3.6 27B on my 3090 Ti.
Of course, this also means that if you try to raise your prices (or, as Anthropic did, squeeze out certain use cases I have), people have a lot of other options. That puts a cap on the pricing power of the frontier labs.
A long time ago (i.e., April last year), I discussed two possible paths for frontier labs—fixed costs for training could keep increasing and they could become natural monopolies... or overall costs could fall through the floor and their capabilities could become commodities.
It’s not necessarily going to truly be that binary—and it’s still early on—but cloud prices for open-weight models are converging at the local hardware cost of electricity—roughly $0.20-$0.50 per million tokens. Anthropic commands a huge premium per token—which I’ve been happy to pay—but would most people stay if they 10x’d their price? 100x? I suspect not.
Despite Anthropic's crackdown, I can keep running a lot of AI agents—because, for better or worse, I don't actually need Claude. I subbed it out with ChatGPT and Qwen without any issue. That says something about the future, even as Anthropic enjoys its time in the sun as the “leading lab.”
After all, if things keep going this way, we’ll be running frontier-level models on our phones in 5-10 years. That’d be because of both hardware and software (though probably still mostly software).
Thanks for reading!
I hope you enjoyed this article. If you’d like to learn more about AI’s past, present, and future in an easy-to-understand way, I’ve published a book titled What You Need to Know About AI.
You can order the book on Amazon, Barnes & Noble, Bookshop, or pick up a copy in-person at a local bookstore.

Very timely, this article from bbg also addresses the question of rising AI costs. Although the cost of compute and AI inference cost is going down as software and hardware improvements are made, do you think overall costs per user will go down or continue to move up? If I had to personally pay $100/mos for Claude Im not sure if I would do it. I think most ppl feel the same. Companies are really starting to incorporate AI into their processes, but for them to continue to increase spending, they would need to be able to quantify the impact on their bottom line.
I agree with you, theres definitely a cap for how much frontier models can change, but Im not sure what that is and what that means for their margins.
https://www.bloomberg.com/opinion/articles/2026-05-26/ai-boom-bankers-love-of-claude-carries-a-heavy-price
Nice post! As someone who tried to run local models on a 16GB M4 Mac Mini (and got horrible performance), running Qwen 3.6 27B on 2022 video hardware is impressive. Wondering what the surrounding machine is and how much the hardware costs (i.e., did you custom build a Windows machine?).