





This is the fourth interview I’m publishing in my series of interviews with experts as part of my research for my upcoming book What You Need To Know About AI.
Today, we talk to Devansh about the use of AI in the legal field as well as upcoming AI trends and other interesting perspectives on AI, especially given the wide range of work he’s done in the field. You can read the full transcript below or listen to the conversation on your preferred podcast platform.
You can also check out some of the previous interviews I’ve published:
Dr. Joshua Reicher and Dr. Michael Muelly, Co-Founders of IMVARIA, about the use of AI in clinical practice
Tomide Adesanmi, Co-Founder and CEO of CircuitMind, about the use of AI in electronic hardware design.
Alex Campbell, Founder and CEO of Rose.ai, about the use of AI in high finance.
As well as an excerpt from a chapter from my book: AI Winters and The Third Wave of Today.

You can learn more about the book and pre-order on Amazon, Barnes and Noble, or Bookshop (indie booksellers).
Devansh is an AI researcher who’s worked with a variety of organizations ranging from multi-national corporations, state governments, and small startups. He was also part of a team of three that beat Apple in Parkinson's disease detection in low resource and high noise environments using voice samples. Currently, he’s the author behind the Substack Artificial Intelligence Made Simple that teaches 185,000+ people around the world about AI and is a Co-Founder of IQIDIS, a legal AI startup created for-and-by lawyers to improve their workflow and efficiency.

Topics Discussed
Devansh’s background
AI vs. traditional software background
IQIDIS and Legal AI
Is accuracy as important as we think for developing AI for the legal field?
Customer feedback about IQIDIS, and do lawyers fear they’re going to lose their jobs from this?
What type of law firms work with IQIDIS right now?
How do people in India vs. United States feel about utilizing AI?
What are you most excited about when it comes to upcoming developments in AI?
What are your fears in terms of what’s coming up in AI?
What does “Chocolate Milk Cult Leader” mean?
Devansh’s background
James Wang
All right, awesome. We are live and yeah, I'm really excited to have you here, Devansh.
Devansh
Thank you, James. I'm very excited here, a huge fan of your work.
James Wang
And same for yours as well. And congrats on the two year anniversary as well for your Substack. That's really exciting. Maybe you can give folks a background on both who you are and how you got to where you are now, whether it's the Substack or IQIDIS.
Devansh
Absolutely, happy to. So, hello James' audience, I'm Devansh. I am an AI researcher trying to cover what's going on in AI research and trying to figure out what is impactful and what is not for building real life products.
I got started a little while ago in 2017. I was part of a team of three that beat Apple in Parkinson's disease detection and real-time voice calls, specifically when it came to very low resource environments and very high noise environments. So if you have a lot of background noise, you are cell network-centric, and you're working on very old cell phones, etc., that's specifically the area we're targeting. That really has formed the basis of a lot of my future projects as well.
Anybody can do AI well when you have millions of dollars of operational budgets, but what happens when you have to really constrain those inputs? How do you ensure that you're still able to match 80, 90 % of the performance, but at 1/10th, or 1/100th the cost? So that's kind of the really special area I operate in, and that led to a lot of places for me.
That led to eventually a Substack for me because one of the projects I was working on—this was for a state government of 200 million people—we were trying to quantify the impact of changing specific public policy on health metrics. So if I move workers from one district to another, what would the impact on diarrhea and health—or STDs—to people in both districts be, how much would one lose or gain… especially when it comes to things like allocating resources.
Do you want to allocate more resources to certain funds? Do you want to cut resources out of certain things? We were able to identify like 60 variables that had no statistically significant impact. So they were just being funded and tracked because people thought they would be helpful. But what we learned is that they're not so helpful. So can we remove those and focus on what really matters?
James Wang
In that case, let’s talk about your academic background. I didn't know the Apple thing in terms of the Parkinson's competition and stuff. That's super cool. So yeah, you must have PhDs, multiple PhDs. What's your educational background, Devansh?
Devansh
Time for most people to be disappointed with me. I don't have any higher level degrees. That was actually the formation reason behind my Substack is during this health metrics project.
What happened is I told my supervisor at this point that hey, I've kind of struggled with getting AI jobs and I think I'm going to go get a PhD because I didn't even have an undergrad degree at this point. So I'm like, I'm going to try getting a degree so that I can apply to these places and not worry because even though they say they don't have hard degree requirements, they'll often filter you out if you don't have anything.
And this is after I've already beaten Apple and I have an algorithm in Parkinson's disease to my name. I have some work experience in machine learning, but my resume was getting caught up with ATS filters. So I thought me writing on AI research, me demonstrating my ability to analyze it, break it down, identify what would be the good next steps with it, would be a phenomenal way for me to actually reach out to PhD schools and do it.
Turns out I'm not really cut out for formal education and academia, but the whole process of writing and understanding research ended up being extremely valuable to me.
AI vs. traditional software backgrounds
James Wang
And do you think AI is different than, say, software or some of these other areas that makes it unique in terms of this? Because I think your background and some of your history is very unique, but you're also not the first person that I've met within AI research that doesn't specifically have a PhD in either computer science or machine learning or statistics or some of those related areas.
Is there something different about it? How do you see it just in terms of how that breakdown works for this particular area?
Devansh
That's a very interesting question. I think even with a lot of early tech software, you didn't have people that had any formal education or training coming in and making a huge splash because so much of those fields are not predefined, well-defined protocols where those degrees can really, really teach you a lot.
Of course, I'm not saying those degrees don't teach you anything, but if you can learn and grit your way through things and kind of figure your stuff out, I think they become much much less helpful because there's so much that's just out there. And like that was kind of where I ended with my second anniversary post also. Fundamentally, these fields aren't as well defined as people think. There are a lot of open gaps and spaces, which means that you can actually carve your way into it. You can kind of bully your way into these fields, which you can't do that for medicine. You can't do that for other fields.
This is not meant to be some kind of an anti-college, anti-educational and altogether just when it comes to AI, there's a lot of open spaces that you can get into. There's also, I think, some differences with machine learning specifically, generative AI being a subset of that, where machine learning requires a different kind of thinking than traditional software. But I don't know if that's a discussion that you were planning to have.
James Wang
No, I think that's an interesting place to take it. I would love to hear what you have to say there.
Devansh
I think machine learning is a lot like gambling and I tend to see a lot of things as gambling, so maybe that's just me. But fundamentally, what machine learning requires you to be very, very good at is working off incomplete information and testing hypotheses on the fly to identify, want to develop on these features.
You start hitting half targets, being like, okay, I think I can estimate this much here, I can do this. There are very few truly principled statements you can make with ML systems. A lot of the times when you're building these systems, you're taking half guesses and you have to iterate your stuff on the fly, which is very different to what a traditional software engineer might do, where you have an entire system and you're more worried about implementation, you're doing this.

I mean, that's where... like fundamentally something like the old school chess boards, which had the rules built in, had the algorithms built in, they knew how do you quantify a scoring system on the board, like they had a scoring function for the whole board, they were doing all these things like do a decision tree search to see what you should play next.
That's where they became so different from deep learning-based chess which you don't understand a lot of the details of and that's why building on deep learning systems, building on machine learning systems becomes a completely different ballgame—because suddenly you end up having to prioritize other things like transparency in your system because you don't always know what all the details are so you need to kind of learn to build around it.
And I think that's where I see it a lot like gambling. I think it's one of the interesting areas about machine learning that I've really come to enjoy because it's kind of like you're taking a lot of guesses and seeing how good your guesses are, which is really fun for me. And also it allows you to expand your abilities because you don't have to know everything. If you can work off partial information, the number of problems you can solve expands dramatically. But also, you might not be able to solve them with depth, so suddenly you start having to be a little bit more careful. I think a lot of teams mess up when they're not very careful.
What machine learning requires you to be very, very good at is working off incomplete information and kind of testing hypothesis on the fly to identify, want to develop on these features.
James Wang
Yeah, and I think there's a huge amount to dig into, a lot of the things that you just said there, including some of the transparency and other stuff that I definitely want to get more into.
And I will say that in terms of giving an analogy to gambling for the guy who's from a hedge fund, I'll probably agree with you, but maybe some of the other people won’t. But no, totally agree with the idea that there's a lot more uncertainty. And I think one of the other Substacks like Society's Backend talks a lot about this in terms of getting into AI jobs, also has a similar kind of theme. But I guess I would love to also get a sense then of how you ended up getting into that and maybe describing for folks what it can be as does too.
IQIDIS and Legal AI
Devansh
A note about Society's Backend, Logan Thorneloe is also primarily an ML engineer. So he's a lot like me, where you'll see similar kinds of thoughts. Other people, they become software engineers first for many years. and then they transition, and I think they tend to have a lot more of the traditional mindset. So I think it just goes to show you, ML is a different kind of mindset and it has benefits, it has huge drawbacks but you have to balance them.
But getting back to your question, IQIDIS, how did we get into it? So to those of you not familiar—because we aren't a household name yet—IQIDIS is a legal AI company that's trying to optimize how lawyers do their work.
What we've identified is that there are lots of inefficiencies right now in the document processing area and drafting. Very large documents can have a lot of time wasted going through every little clause trying to identify how different clauses might play with each other. That's a huge problem that traditional models like GPT can't solve. Specifically, I have a clause here, I have one clause in another chunk, but these two are linked contractually, but because they're in such different places, AI might not be able to identify that they are important and they are in fact very important because you have both of them together.
And suddenly there's a huge concern for anybody signing this. So being able to do that kind of nuanced legalistic analysis at a high speed is something that is the core driver for IQIDIS.
Right now, we're a few months old. I met the CEO a little bit ago. We kind of hit it off at a legal tech conference. When we started speaking, a lot of what he said resonated with me.
That's kind of how the whole thing got together. We started meeting every Saturday just to play around with different code bases, different models, different ideas. And then we just slowly committed more and more to it until we suddenly had this company. And now we've got some paying customers. We're hiring people. So it's been a steady growth.

James Wang
And maybe I want to ask a little bit more about just the area of legal AI in general, because it's not a new one, right? At least as far as I've seen quite a few companies over the years and quite a few bodies buried in terms of legal AI. But then again, there's also now a big competitor that I think just recently made more news. And you can feel free to comment on them or not. This one's obviously Harvey, which just raised from Sequoia $100-and-something-million.
It had a $3 billion valuation just a week or two ago or something like that. But yeah, a lot of these startups have also failed just within the legal field. So I guess, whether you want to comment on Harvey or some of these others, what makes the legal field interesting for you and what do you think is the distinguishing factor for your company in being able to make a difference here?
Devansh
So I think it's always good when you're talking about legal AI to split up the kinds of companies you're talking about. And it's a good example of what we talked about earlier with the different kinds of mindsets. You have companies of the past, CaseText, etcetera.
They make a lot of money. And what they're doing is, you enter certain parameters and we'll make it searchable. So what they are is a search engine. A lot more traditional in terms of the technologies. It’s a database. It's an interface on a database management system. You just put in some details, they'll give you some cases.
The problem with a lot of the new generation of technologies is that they saw the rise of ChatGPT and they're just copying it—which is good at a certain layer. It's not a good complete infrastructure to build your tech around.
So that's why we're seeing so many people raise tons of money, legal tech has raised over $1 billion in over five, six years now. And none of them have eaten the market like they were supposed to. If you give anybody a billion dollars or, you know, $50 million and they haven't done anything, there's fundamentally something wrong with the approach.
And what happens is, what I can comment on is that we studied the market really really well, and what we often notice is that the competitors tend to be wrappers around GPT and they're trying to do something like fine-tuning. They're trying to score the outputs in some way, some kind of RLHF or whatnot. Now, this is done by a lot of large language model providers to improve the quality of their outputs. So people just look at this and assume this is how some AI company should also operate. Because if ChatGPT can do everything, why couldn't you just fine-tune on legal data and improve that?
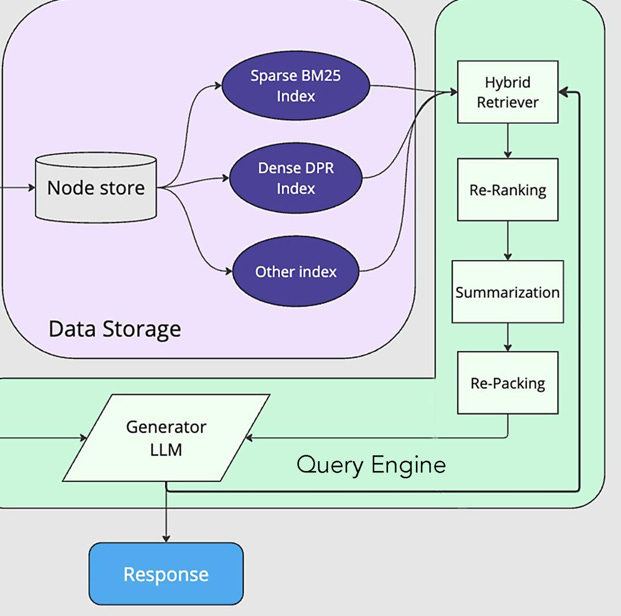
![How we built an efficient Knowledge Intensive RAG for Legal AI at IQIDIS [RAG]](https://substackcdn.com/image/fetch/$s_!qU-g!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F035b6c56-f04e-4fcb-954c-acd2c96b1e7c_1000x495.jpeg "How we built an efficient Knowledge Intensive RAG for Legal AI at IQIDIS [RAG]")
Fine-tuning as a way of improving quality, specifically injecting information into your language models, is an incredibly inefficient approach. It doesn't work. It adds all kinds of new security risks that you didn't know beforehand. And it's just a very dumb way to do things. It's like trying to make the ocean less salty by dumping buckets of water into it.
What you have to do is you have to optimize for specific protocols. That's why having a team of lawyers is supposed to be helpful, or having lawyers in your team is supposed to be helpful, because they will tell you how to solve the problem. They will say, these are very specific issues that I'm seeing that we need to solve. Like I gave you that contractor view example. That's a very specific problem. It's going to be there in law. It might be there in some other places to some degree, but it's a much more prevalent thing in law than something else. So we need to know how to solve that problem.
One of the people I worked with, consulted with, they're doing medical research, and for them, you have chemical names. If you change one letter in that chemical name to something else, you might get a completely different chemical. And this is like, cosine similarity based search, which is what pretty much all the search and LLMs are based on, will put these two chemical names very close together because they're, they should come together, but they should not be together, they should be very far apart in the space. So that's like if you were solving for a medical based LLM system, that's something you would prioritize very highly.
So just going back to the earlier point about would you, everybody has a set of problems to solve but and it's largely the same set of problems but how do you prioritize between sets changes a lot and what we're noticing right now is, to me, when I'm seeing people raise this much money I'm licking my lips because what you're telling me is you haven't figured out what to do, yet you've raised all this money, but you're not able to keep scaling, and the hurry, specifically the valuations are going down
That I find very interesting. I don't know what's going on. I'm not going to say they're failing or they're succeeding but I just thought that was a very interesting approach. I've spoken to a few people about it and that's generally the vibe we get that hey, this looks a lot like GPT, this feels a lot like GPT, we're not able to, this doesn't solve the substance of work that we'd like it to.
James Wang
Right. Just to summarize, there is basically within the space of the model itself, there is an inherent way that a lot of these LLMs are built out, and they do well in terms of the ways that they do chat, and these other things that prompting that they're specifically optimized for.
And what you're saying is just within even the space of the associations, the internal vector space and everything, you essentially have to do something very different almost from scratch, or just something more specific to actually solve the specific problem area that you're looking at? Is that roughly getting it right?
Devansh
Yes, and often it doesn't have to be something grandiose, but knowing that this problem exists and that solving for it can tremendously increase your model, your system's capacities. So what people are trying to do right now is they try to fine tune it by scoring the output. So they're trying to fix it at the last layer, which is the output layer. And you're trying to propagate this back into the functions of the model and associations, but this is not a very efficient way to do things.
The reason something like OpenAI or Claude or Gemini would do this is because they are they are a horizontal player—they have to solve for medicine, poetry, like reviewing movies, summarizing books, like these are very different tasks, so this is a good enough one-size-fits-all system that can be generalized, so the same error output does this so you can pay a lot of labor to do a lot of different tasks.
We're not trying to do everything. We don’t want to solve them all. I don't care if my system is worse than everybody else at reviewing movies or writing code. So when I don't have to worry about that, then I can really start figuring out specific pipelines and building for those specific challenges. Whether that's better search, scoring things better, scoring your sources better, building argumentations better because there are different ways you can build those argumentations, taking user preferences to build drafts and memos and whatnot. When you're able to start doing that you just get so much richer features with the same baseline level import.
We've been bootstrapped, we haven't raised any major capital for now and our user feedback is constantly, “You guys are really, really good, you're the best in the market.” We're the only ones who offer free trials with no lock-ins because we know how good we are, we know that when people use us, they'll stick to us. And that's because of how cost-efficiently we can run, which means that we're just able to outperform for very little in inputs.
Is accuracy as important as we think for developing AI for the legal field?
James Wang
And I think that it's fascinating because one of the things that you're saying is that you've been emphasizing workflow.
You've been emphasizing workflow and task specificity just in terms of a lot of these different pieces that you're talking about. I think one of the interesting things, especially within law, one of the things that I've mostly been hearing about has generally been accuracy. And I think that's partially because there's been a few high profile cases, including lawyers using ChatGPT when they really shouldn't have, and it making up court cases and hallucinating and whatnot. And my favorite more recently was a Stanford misinformation expert who is giving testimony as an expert witness on misinformation, and he basically had some made up stuff in his testimony. Later on, he admitted it's because he was having ChatGPT write it.
So the legal field especially seems to fall into this trap a lot. I guess I'm curious, why haven't you been emphasizing accuracy? I've heard plenty of startups in terms of the legal field talk about how much more accurate they are than OpenAI, ChatGPT and whatnot for legal work or other things. Why is the way that you're describing this so different?
Devansh
Because I think accuracy is not a good metric at all.
Because what we call hallucinations is just based on luck and can branch into various subcategories. And this exists across fields, but how we've broken it down for IQIDIS is you have a hallucination of a fake case citation, but you can also have hallucinations where you have real cases and you built the wrong analysis on them.
You say they do say this, they don't say that. And these are two fundamentally different problems. With one of the cases we were working on very early on, this was a challenge we had. We would upload a document, we'd say what is the main problem here? And it was picking up the wrong problem. And that's also a kind of hallucination, but it's a fundamentally different kind than the one of the first types. So you break them down separately, like when it comes to workflows, for example, our case citations.
A lot of the people try to solve it by only fine-tuning on real cases, or they might find fake cases and keep feeding that into your model input and do that. Our model has some capacity right now to generate case citations, but our main system does not generate any case citations. We have a specific subsystem that pulls out from our databases, cross-checks across a few different places. If it finds one, it will plug it in. If it doesn't find it, it will just say, insert case here, this category, and leave it. This doesn't work all the time, which is why I'm not trying to emphasize this. We still have to iron that out, but that problem specifically is a very high resource problem. It's a problem that requires a lot of trial and error because you have to integrate where the case places themselves. There's often issues within the case citation databases that you need to account for. You need to account for the specific ways you pull out that data, analyze it, and all of that.

As long as you have a transparent system—this is why I'm such a big fan of transparency—you can actually kind of have a lower accuracy system. You can trade those off because if I can show you where everything is pointing to—when I'm reviewing your documents, these are the points of your document I'm talking about. When I'm making claims, this is why I'm making these claims. As long as you have that, users can review it much quicker.
Maybe something like, imagine you're a lawyer. You spend five hours on a document draft, which is very, very low ball. But I like to give low ball estimates so that people don't question the math. And you would normally spend 30 minutes on document drafting or on review where you have to check, or maybe let's say 10 minutes because you trust your paralegal to have given you the right case citations, you trust your junior lawyer to have built the right case law analysis, etcetera. You're just checking, okay, is the structure in good? Is the formatting good? Based on these cases, can we argue this? Can we argue something else? Should we emphasize or de-emphasize certain things? So only 10 minutes of review.
What we do is we drive your time down to one hour of the pure drafting and whatnot and maybe you should do half an hour of review because we give you all the places you should look at. The case citations is why we pick these cases. These are some alternative strategies you could have built on and these are the alternative cases in your document. These are the most important aspects for every query. We decided that these are most of aspects, chunks and whatnot. So now suddenly, if you're a very conscientious guy who wants to test everything, check everything. It'll take you maybe 20 minutes, 30 minutes. But the net delta on your time stamp is you went from 5 hours and 10 minutes to 1 hour and 30 minutes. So that becomes a huge factor.

I think that's why people don't realize this, but ultimately accuracy itself is not the metric people want. It's just I want to save time doing things and there are easier, better ways to save time, especially when you're a startup. It’s like pure perfect 100% accuracy is not something any startup can nail and anybody that claims to is lying because it requires a lot of trial and error. It requires time in the market. It's not even a money issue. It's a time issue because you have to figure out how things are being done. Things are constantly changing. You have to keep ironing them out.
Google still hasn't figured out accuracy on the traditional search—and that’s a trillion dollar company around for many years—trying to compete on something difficult, with that ROI… that's not what users want. That's what they say they want. But sometimes you have to ignore them and read between the lines, and see what they really would get value from. That's just something that I don't think is a problem with solving and anybody that's coming on and telling you that they're solving it is, in my opinion, not understanding the market.
I think that's why people don't realize this but ultimately accuracy itself is not the metric people want. It's just I want to save time doing and there are easier, better ways to save time, especially when you’re a startup.
James Wang
Yeah, I totally agree with that. I have had more than one occasion where I wish that certain pitch meetings were shorter because I walk in and the startup tells me, “You know, the thing that we do is we can be 99.999 % accurate and have no hallucinations.” And I'm like, okay, I wish I was not in this meeting because I don't think you really know what you're doing. And also, essentially, it's probably a dead end in terms of this.
I'm really glad you got into the transparency thing because I've also had conversations, including with lawyers, where the issue is, “Hey, let's just say that you really are able to get this thing much more accurate without hallucinations…”—and that's kind of an interesting concept… Because, in a way, if you sort of look at the architecture of LLM's work, everything's a hallucination. It’s just certain things happen to be true and other things are not. But you know, it's all the same to the LLM and that's why you end up with it.
Putting that aside, let's just say somehow you're able to drive that rate down to one in 10,000. Only one in 10,000 case citations is wrong. Does that save you time?
The reality is no, because the thing is, if anything, that high accuracy rate is bad because suddenly everyone feels super comfortable just trusting the system to have gotten it right all the time. And then the specific time when you shouldn't have and get it wrong, you look like a complete moron in front of the court because that court case is not true. And you have to admit the reason why that happened is because we used an AI to generate this thing and we didn't check it.
So ultimately, I've heard the same thing from the market. And I'm really glad you brought it up. I've heard lawyers who've used different legal AI stuff say, “I'd much rather this thing gave me an auditable trail that I can check and see for myself that it's accurate and trusted than just making the entire thing for me be a black box and then just need to trust it, because at that point I'm going back and checking every single case which means that ultimately I'm not actually saving that much time at the end of the day.”
So yeah, I'm really glad you brought that up and basically addressed that too.

Devansh
This is what people don't understand about building sensitive AI applications. I did this with healthcare before, so that's where I have this very front and center for me. I could go and tell people something, but how do I justify it? I can't just say my machine learning model knows best, just trust this model configuration and this is good. Our lives are going to change based on this configuration.
So you have to understand where that system comes from, because even when we were doing Parkinson's disease earlier and now this, it's the same story. Accuracy means nothing. It's a nice to have, but what really matters is when people evaluate the data, can they see, based on this data, this is why the model is picking this. So when we're looking at healthcare metrics, that's why we had the quantification of how important this variable is. Because any recommendations we were making, we’re making it contingent on, okay, you're changing these variables, this is how much it [changes] the score, this is why we're doing that. The more you explain something to people, the more they can trust your system.
It's quite paradoxical. So that's actually one of the most interesting things we actively tell people—we have a 10 to 15 percent error rate and you love us anyway because we have a 10 to 15 percent error rate of trying to solve much deeper problems.
The time delta for the ROI—given how much you're paying versus the value you get out of it—is going to be insane. That's the only value which we really have and need. We don't want to get 100% accuracy on a very small problem with your task because ultimately that means nothing.
What we want to do is we want to save your time and we want to save your time by tackling very large problems, making them 80% easier for you, and then these little 20% plug-and-plays you can do yourself. We don't have to do everything flawlessly to be useful to you on a day-to-day level.
Customer feedback about IQIDIS, and do lawyers fear they’re going to lose their jobs from this?
James Wang
Going off of that, then, what has been the feedback from your customers in terms of their overall idea of it? Do you get a lot of fear in terms of them losing their jobs, and scared of the AI that you're putting forward?
Devansh
Not the lawyers we've worked with so far, but I would say there's a huge sample selection bias there, because what's happened is we did a few articles about IQIDIS and they trended. They were shared on Facebook groups and whatnot.
Because of that, we have a thousand plus signups in our pipeline, I think close to 1,500 at this point. So the people who we are signing on, we haven't even started tapping personal networks yet.
These are all people who found out about IQIDIS through somewhere, have no personal connections to us, and then chose to demo the product. And I think that kind of person will like it.
If you're signing up for a product, you're probably likely to be much more experimental and a lot more honest, and that's why a lot of the people we've used have also already gotten experience with GPT and cloud and whatnot, and to us, that's one of the biggest blessings. It's much easier for us to show how good we are by showing the competitors. One of the best things for us has been running the query side-by-side. And we just show, like, listen, we can do this, we can do that, often if you're loading a very large document. They can't even process it, like the cloud has document limits. We're able to process all of these and give you much better outputs so that has been a huge factor.
I think there is some fear in the market. From what I hear, a lot of the people who would send me emails, people have spoken to, off, like you know, just in my day-to-day life outside of my writing outside of AI, there does seem to be a large fear, but I think that's just the nature of technology. There's nothing you can really do there.
It's going to sound kind of, I don't know, psychopathic, but ultimately, for any technology... Technology has never been adopted easily. You just kind of have to bully its adoption into the world and hope that what you're pushing is good product and not something that's fundamentally misaligned with the people, and it won't help people out.
We'd like to think that our product is really, really good and it's really, really helpful. Our users agree and we focus specifically on smaller shops, smaller firms, which don't have the resources of large, Big Law, because they're the ones who do 80 to 85% of law. That's the majority of the lawyers and these are the kinds of people, if you can optimize their workflows, you can really make a difference in law. And so far, all the users have loved it.
Obviously there are some hitches here and there, but by and large we've had really positive feedback. So we think we're doing a good job. If we do end up destroying something for the worse long term, I'm sorry in advance. We did our best.
We focus specifically on smaller shops, smaller firms which don't have the resources of large, big law because they're the ones who do 80 to 85% of law… if you can optimize their workflows, you can really make a difference in law.
What type of law firms work with IQIDIS right now?
James Wang
Yeah, I mean, you preempted one of the questions I was going to ask, which is the type of law firms. And if I was to guess, it’d be the smaller law firms that themselves have labor constraints and time constraints, where the biggest issue is they don't have enough people to throw problems at versus, say, one of the big law firms where they have an infinite number of associates essentially to assign to any specific problem that they might have.
Devansh
They [Big Law] can also spend a lot more on tools, like a lot of the competitors are extremely expensive and they have lock-ins. So, like lock-ins, are you signing a contract that locks in a few months, and you'll pay this exorbitant amount of fees, and you have to buy at least a certain number of seats. They're not even going to sign you up if you don't buy a certain number of seats. One person I know had to bring on 30 or so people just to demo the product.
That's not how most smaller law firms operate. That itself has been a big pitch for us. We just say, listen, we're not going to lock you in. Here's a Stripe link. You get a trial. And then if you keep liking it, it'll start charging. If you don't like it, you just cancel the subscription. You want to email us, you want us to cancel it? We'll do it.
And that will be that. And so far nobody has even tried to cancel it because once you build a good product, people do appreciate it. I think the fear comes when you're not familiar with the technology. Once you give people exposure to it, they themselves become much, much more comfortable with something. And then they start to realize maybe this isn't what people are making out to be. When you're an overworked lawyer in a small law firm who's suddenly able to spend more time with their family, I think you've become less concerned about whether this technology is going to wipe you out of existence.
James Wang
Yeah, and I think that's great. I mean, with all of these interviews, I have found very, very few instances of true cases where you're basically going to suddenly wipe out the humans with AI, except maybe for ones that perhaps shouldn't exist.
And this is like some of the article mills, someone who's forced to be a writer for the top 10 new trends in fashion for the year. If you threw that into ChatGPT or you asked a real writer to do it, it's very hard to tell the difference because there's ultimately no human touch or creativity or anything else that is really in those articles. And maybe some of those jobs shouldn't exist.
But ultimately, even for these, it sounds like they would use more people, but they're small law firms. They don't have more people. And to be able to actually do their jobs and deal with the limited resources they have, the productivity increase with bringing on AI in this way is very helpful. But they're not mass firing all of their associates. They're not mass firing all of their paralegals, it sounds like.
When you're an overworked lawyer in a small law firm who's suddenly able to spend more time with their family, I think you've become less concerned about whether this technology is going to wipe you out of existence.
Devansh
Exactly, their problem isn't that they need to fire anybody. They need to hire 10 more people and IQIDIS is just what helps them suddenly fill out that labor gap. Instead of 10 now they only need two more and they're able to keep on taking on so much more work. That's been the biggest advantage for us—we're just helping people do better work for lower costs and faster timelines. And when this scales out to entire law adoptions, you will see the cost of court cases drop. You will see the time it takes to drop. And that is when the true legal revolution happens because it's not as though law firms will start making less money.
The price of Coca-Cola is cheaper now than it was 100 years ago because of efficiency in the markets, general standards of living, improvements, etcetera. Coke makes a lot more money now because you open up the market so much more that your margins become insane, economies of scale become insane. And that's really the pitch we're making is you will be able to do so much more work, so much faster, so much higher quality that suddenly what was a 10 cases become a thousand cases, and they're still done much more efficiently. So more people will come to you, more cases will come to you, and that's really the pitch we're making. It's a pitch that a lot of our users have resonated with and that's where I think there's a lot more excitement than there is fear.
How do people in India vs. United States feel about utilizing AI?
James Wang
I do wonder sometimes whether or not this narrative and this situation would be very much different if instead we were in a situation where we have a bunch of unemployment, a ton of population growth—instead of where we truly are, which is an aging population, a shrinking workforce, and everything else. But I guess it's hard to say the counterfactual.
But regardless, it does seem like it's hard to actually find many fields where you're actually seeing, “Hey, we're going to lay off or get rid of a bunch of people,” versus we had too few people to start with.
Devansh
I can give you the simulation for that case because that's India. That's where I'm from.
James Wang
Yeah, we'd love to hear more about that in terms of what you think.
Devansh
There is so much excitement there because that's the, I guess, the one difference between that is America is a rich country and India is not a rich country. Specifically when it comes to wealth differences, it's bad here, it's horrifying there. So from that perspective, people there appreciate this idea that they are much more there than here, which is ironic because you'd expect India to be the one place where they're worried about labour and what not.
They are worried about certain aspects of it, but if you can make things happen quicker, if you can wipe out court backlogs—this is why my CEO and I really connected. I'm worried about the court backlogs that happen in India: this is why I was interested in legal AI—I've been for many years now—there are court cases that can take up to 10 years to get an approval, so you go to file something and then the case comes up 10 years from now.

If that's a case on unpaid wages—which is much much more common than you think—the unpaid wages, the guy who's not able to pay them… this person might not be able to survive for 10 years. Like what are you going to do about that? It's a long time. So that's kind of where we wanted to go.
That's one of the areas we have really resonated with for the long-term vision and that's where I think people who come from that kind of an environment can truly appreciate how much resource differences and wiping out these things make because I think with America, you tend to be a little bit more spoiled. You tend to see things that work well and that's it. For any countries where you have a large population growth and unemployment, etcetera, that's all you would think that creates a hindrance for AI adoption.
But this is the kind of place where people know that we need things to happen quickly, we need to move quickly, we need more efficiencies in the market so that people have more opportunities and that's where traditionally like that's where there's a lot of excitement there… and unfortunately a lot of exploitation there as well because people get scared into buying courses, products from scammers, lower education and higher fear tends to be a very common problem there. But there is an excitement that can be felt. I think anywhere where you have any kind of scarcity, whether that's a scarcity of time and resources here or it's a scarcity of opportunity in a place with high unemployment and a younger population. I think that's where you will start to see technologies that are efficient make a mark there.
James Wang
Yeah, and I think that's a great point. And this gets a little political on my end, but not really on any side of the spectrum. I mean, I myself come from a not so affluent background. In fact, one would say a very poor background in terms of early on.
And yeah, sometimes when you sort of hear and see the way that, you know, a lot of different wealthier societies treat things, it's like, we want to freeze things in amber because we kind of like the way things are and are not interested in progress, whether or not they say that straight out, but because things are pretty good for us. So why change?
But when you also have folks who really know that, like a lot of things, it'd be great to change because things aren't great where they are now. You get a lot more urgency and you get a lot more impetus in terms of that. So I think that's a great perspective to share as well.
What are you most excited about when it comes to upcoming developments in AI?
James Wang
So I think I want to now get a little bit into some of your thoughts for where AI is going as well. Like I looked at your trends article, I think two trends in particular that we both share in terms of thinking are really interesting coming up, is both the rise of inference time computing as well as some of these smaller, more specialized models.
I guess just in terms of your perspective on some of those future trends, like how do you see some of that stuff coming about? And maybe you can talk a little bit about the adversarial stuff too, which I think you put up first because it feels like you're most excited about that.
Devansh
So that was lower in terms of how confident I was. So it was put first because I think it's the second trend out of six.
James Wang
Ah, ok.
Devansh
Though, after the Libgen case, I actually would rank it a lot higher. So let's go in order of least importance to where I think these fit in.
So in my opinion, the least important would be the SLMs [(Small Language Models)] and whatnot for the shorter term future, and the only reason why I would put them lower is I was on the boat that they'd be very important two years ago, but since then what's happened is that costs have gone down so much, and I have a bunch of inside conversations going on with people, and what I hear is that it's probably not going to go up tremendously anytime soon.
So the ROI perspective for me to use a model like GPT versus just using a smaller specialized model is not actually very high. It's actually negative, because keep in mind it's not just the cost of using a model—like people think, oh, an open source model is free. It's not. You have to host it somewhere. You have to actually hire somebody to build models on top of it to run the inference, to do all of that. If you're trying to customize it in any way, that's all costs both in time, in labor, and resources.
So, from that perspective, I think the larger models, first off, they should all fire their marketing departments because the fact that people think that there's a close fight between closed models and open models is absurd to me. And that's only possible because everybody looks at benchmarks, and benchmarks are kind of useless.
So I think the cost differential of using a closed model for now is so much higher than I would probably stick to it with the only caveats being if you're changing specialized models for very specialized tasks, such as intent classification, if you have a math workflow and you're using a specific kind of tokenization and model for that, where in these very specific challenges, I can see the ROI differences really popping out, but other than that I actually don't think it's that valuable, where it might be valuable is at the edge, inference at the edge, which I think is definitely from a long-term perspective extremely promising. I am very excited for it. But the only reason I'm putting it at the lowest tier is in my opinion it's not a very good investment—it's not something that will return money within the next one to two years—at least you won't hear about it. It's something that will happen in the background and you might see startups come up and raise a few rounds. The real meat happens four or five years down the line. That's where it really starts to make an impact.

Next—So now is an interesting place. Depending on what kind of a profile of an investor or person you are, think the rankings will change. I'm going to put adversarial perturbation as second because it's not for everybody. It's not going to be everybody's cup of tea.
So what it is, because this is a very unknown field right now, is you change inputs in such a way that are undetectable to humans but will break models. So I have a very good example of this that I used recently, where I put a picture of me doing bristle and jiu jitsu and I change it in such a way most people can't even tell what the difference is. When you ask Gemini what it is, it crashes out. Sometimes it says that's an airplane, sometimes it says there's a... like two people fighting each other. There's just me in the picture and there's no other person anywhere. And my favorite is it says this is an anime warrior woman with bright red hair who's wielding a sword or something. And I thought that was absolutely hilarious.
So the reason people might not be sure where this becomes useful, but you can do this with text. You can do this with images, and where this becomes very powerful is if I'm an artist, a lot of artists don't want their data taken. The reason why Libgen makes me much more optimistic now for it is that data publication houses are going to start wanting the same thing. I've made all these books, I don't want the people training on them. So far, they might have thought they're probably licensed it through one of the legal sources. But now that they know that it's going through libgen and whatnot, if you can perturb your books so that they become useless to your models, the only way to train and improve a language model will be for you to buy these high-quality books from the sources directly.
Politicians are very interested in this. They don't know the term adversarial perturbation. But they're looking at it in terms of these tend to cause headlines. So can we create testing protocols for this? Because a lot of the research around AP is kind of its cousin jailbreaking, which is, can you get ChatGPT to build a bomb with certain tax inputs and whatnot?
Who else? I think there's one more group. I can't remember off the cuff. But these are all groups that are distinct. They all have a very high distribution rate. A top artist can get you a lot of views. A top politician can get you a lot of attention. Top publication houses obviously have a lot of very strong networks. So what this means is when you have all of these kinds of slightly divergent groups all converging onto the same use case, which is test this thing out, make sure these things are working, or corrupt your input so they can't be used in training data without licensing.
What you tend to get is you get a lot of money flowing in. You have a lot of opportunity flowing in. None of these three are traditional AI customers, which means it opens up a new market for you. So this is one of those areas where you have to invest in people that can create markets. This is not a market that exists right now, but that's why I am excited about it, because I like to play in a little bit of the risky places where you put in a lot of money and you get very outsized returns and that's where I'm very excited about the serial perturbation.
The number one, I think, will apply to everybody across the board and is generally very interesting, is inference-time compute. That's kind of what we're doing at IQIDIS, it's just not under that name.
So right now people are only looking at it with a very narrow lens of having the LLM spend more budget computing things, which like, yeah, no shit, it's gonna give you better results. But if you really think about it, there are some really profound implications, because what you can start doing is you can tinker with the way AI makes its calculations.
I think we connected over my articles on the medical side of things and O1’s terrible medical performances. You'd be able to do things like... One of my biggest critiques was that it's not incorporated in the Bayesian priors at all, and that's a huge no-no for any kind of diagnostic, so if you're able to incorporate that, instead of trying to force an algorithm you can just create these mathematical functions within the system that does it. Like agents, I think are very similar to inference-time compute because they have the same philosophy, which is instead of trying to do everything—like traditional language models, you're trying to preempt every kind of task beforehand, you give somebody a frozen model and you run it there. Instead of doing that, what you're trying to do is you're trying to build a more flexible system that can work as you're developing and building on top of it.
So inference-time compute, whether that's directly through chain of thought or not, but also through other methods, which I think are more promising, which is you have an evaluator score, you have multiple chains of logic that can branch out and help your AI develop. I think that's going to be much more powerful. I think it'll have lower returns than the adversarial perturbation because it's kind of a space a lot of people are in, and you need to put some money in to crack this field out. But it is something that a lot more people can invest into and still see decent returns as opposed to something like adversarial perturbation where I think you're going to have four or five big players that really create the market and then maybe four years down the line you'll get more. You can start investing in startups more consistently because now that field has been more established. So that's just my answer.
James Wang
Yeah, totally. I think that makes sense. And I thought the adversarial perturbations were really interesting too when I saw it, because I'm actually pretty familiar with some of the adversarial work, but specifically from self-driving cars, right? Like for example, sticking crazy things onto stop signs or other stuff that for a human, you can't even see, but completely screws up the recognition that the self-driving car has.
So it can't see stop signs, for example, it can't do whatever. It interprets a car as an open road. So there's some really interesting research that, I think it was Carnegie Mellon and some of the others that were doing on this where they're basically showing a bad actor could just completely screw up all of these self-driving cars if they're relying on some of these vision models that can be easily tricked with these adversarial perturbations, with stop signs and other stuff. So I thought that was kind of interesting seeing it and having an idea in terms of business models and other things, especially for creators.
For the inference time compute and some of the other stuff, definitely agree. And actually the funny thing is, I don't know if you had heard one of the other interviews here with CircuitMind, which is a board level electronics design company that essentially does a lot of this layout design, other stuff. But they had also mentioned it's like for some of the aspects of their validation and layout and other things, they actually have a deterministic model, a very sophisticated like physics model, other stuff that essentially is not an LLM, is not deep learning and is not these things. It's less sexy in terms of that side of it.
And everyone likes to hear about Elixir, which is their LLM-based model that reads data sheets. But ultimately, a lot of their value is also just this deterministic model that because they have a brilliant physicist on the team, it helps actually be able to build that. But I think some of the things that you're saying do go towards that and do make a lot of sense.
What are your fears in terms of what’s coming up in AI?
James Wang
I think as we sort of get towards the end here, I just have a few questions. I think one of the things that you had mentioned recently was fears about AI, and I'd love to hear what you fear in terms of what's coming up in AI?
Devansh
So it used to be the environmental load I was very concerned about. I'm not saying I'm no longer concerned about it, but I've read some fairly convincing arguments. Maybe I've just been psyopted into believing that it's not a concern, but I think that's less of a concern than it used to be. I still haven't fully made up my mind. I'm going to read some more before I do, but last year, if you'd asked me, I would have definitely said the environmental load, and I would have been very confident. I'm probably wrong on how much, how confident I was at being a problem last year.

What concerns me right now… Maybe I shouldn't have led with this, though. I'll be wrong, because now that might invalidate this one. But it has been a general, I look at a lot of people using AI, and it's starting to feel like they're replacing it with their thinking. And that to me is just deeply concerning.
I saw the study where they were using AI to rewrite conspiracy theories and beliefs. At first I wasn't that surprised by the results because AI is pretty convincing. What surprised me is how many people, including some so-called AI critics, were celebrating this as a task, like I don't think this is the can of worms you want to open, because if you're starting to go down that route, you're starting to give people power to influence large language models—people are already starting to use them as is without thinking—people have been starting to use them like, create this, do this, do this draft with me, like you mentioned lawyers who were just using it without checking their work.
I know people who will literally use it to ask for priorities like, hey, help me figure out what I should do here, here, and here. And then whatever the AI model says, that's what they use. Like very little modification. They don't even critically think about, oh, is this what I want to do?
There are people, when I was writing, I was trying to hire—I was thinking about hiring some people to help me with the research and whatnot—and I would try to help them to like, critique my articles. That was my interview. If you can critique my articles, give me how you would have improved them substantively, then you're hired.
I look at a lot of people using AI, and it's starting to feel like they're replacing it with their thinking. And that to me is just deeply concerning.
Often I would hear these critiques, and I'm like this isn't really a good critique because I already considered this, and then I'll try to poke them a little bit more, where are you coming off of this, and ultimately it was GPT and they didn't even think about. And these are like some really smart people, like these are people who I know have done some very good work in the past, but they're just not able to and they're not trying even to formulate thoughts. So the way people are just running towards this “let me use AI to think about that,” that's concerning to me because I feel like that, combined with the fact that so many people seem to be very pro-censorship.
It's crazy how quickly people become pro-censorship. How quickly people went to it, starting from, “we have to stop misinformation. We have to stop this,” which I agree with. But when you start cutting things out, you start joking, it's very easy for Google tomorrow to say, our LLM is going to stop saying things or suggesting things that might be considered as problematic to us. There's a problem I've seen already, by the way, is if you try to... I've written something critiquing the way LLMs are designed, the way they've been done. And for example, when I put them in GPT and ask them to review it, it will say, oh, I'm going to score this a little bit lower because you're not giving a balanced view of language models. You should have mentioned how great language models are as well. In the article that's explicitly stating, these are my critiques so that we can improve on them, like I think these are useful technologies, so what happens when they start to be used en masse?
What happens when they're part of recommendation systems and whatnot, and you can use those to tweak certain voices, suppress certain voices, increase, enhance other ones? That to me is deeply concerning. It can be used [and] it will likely be used [this way], because if you can use it, game theory-wise, why would you not? Why would institutions not use it? Why would governments not pay off these language model providers to toe their party line?
But the number of people that are being almost open-handed accepting of things is, to me, probably the biggest concern. People don't appreciate the value of freedom, even when it doesn't lead to outcomes you don't want. I think it's still important to have some degree of freedom and be very skeptical of technology, specifically which acts as a force multiplier that can start curbing freedom.
James Wang
Yeah, totally. And I think this has been a hard lesson for the, well, for the Western world to learn. Because if you think back, Bill Clinton once said, because the internet is coming, China will suddenly become a free and open society, because once the internet becomes prevalent in China, trying to contain freedom, or whatever it is, free speech is like nailing jello to a wall. And it appears that technology has allowed China to nail jello to the wall quite effectively in terms of these things. And yeah, it is kind of concerning, I agree, like culturally, where people have forgotten why one would be suspicious of curbing free speech. There are always obvious cases that it seems like it looks good. But who determines that?
And then eventually who determines that and then who watches the watchers? It's just a very hard. Even if you think about it from a game theory perspective, it's a very hard problem to solve if you actually want to preserve things. It very quickly just becomes, well, whatever the watchers decide is the right answer is the right answer. It's no longer a debate.

Devansh
And I think the perfect way to build off that Bill Clinton example is people don't understand this about technology, but technology is fundamentally a conservative force. Conservative not in the way Americans use it, like Democrats and Conservatives, but from a more traditional sense that it preserves the way things are done. So there was one way for a sewing machine to stitch things effectively. You get a machine now, it's only going to do that one way.
It's going to do 20x faster, but it's the same. You suddenly won't have the little bit of deviation you might see. Language models have been shown to reduce the semantic diversity of your text because they'll produce long one-line lines. And that's kind of what you want. If I'm diagnosing somebody medically, I won't trust a doctor that looks at the same set of diagnoses and says, one day this person has cancer, the other day this person has some muscle sprain, right? You trust somebody who says muscle sprain five times, cancer five times, and that's kind of a hallmark of good technology—same inputs same outputs—because then it can be done at scale and you can trust it to work.
But what that means is if you start to incorporate certain tendencies into your technology, it will magnify those tremendously. You know, the internet didn't reduce inequality, even though it reduces access to opportunities. What it's done now is you suddenly have more privileged people who have the luxury to spend that time, learn more, do things. And that's why I count myself very lucky [with] my writing, my research. I had the appetite to take that risk because I didn't have to worry about working three jobs. I have a friend from college, he was working 80 hour work weeks in college in customer service. So to have expected him to then be also like, we started in the same place.
For him to have had the time to do the things I was writing, to dedicate himself to research, just would not have worked. And because of that, I built this newsletter. He has not built the newsletters. He has a fairly decent job, so I'm not going to say he's in a terrible place. But in terms of our career prospects, they're really not comparing anymore. And that's not because I'm inherently better than him. I do have a high opinion of myself. I think much more important is the fact that I just had time to spend on this and he didn't, and that's what the internet has done is now suddenly when you're privileged you can build up your resume much much earlier, you can do much more in many more things as opposed to a kid who doesn't have the family background, who doesn't have the exposure to be able to do these things. Like if you see your parents working 80 hours, you're not going to think about, let me learn about stock investing and do all of these things.
So in many ways, and I think this is backed by the data, inequality gets worse. And that's kind of why I've become very leery of any attempts to curb freedom, because you build that into technology now, five years down the line, it goes turns into a monster that you weren't expecting, which is why we have to specifically with freedom, you know, that's something that is a very adversarially tense place. We want freedom, institutions don't, because it's better in that interest. So you want to be very skeptical and you want to fight back at any opportunity where it might even look like it can progress somewhere.
The internet didn't reduce inequality, even though it reduces access to opportunities. What it's done now is you suddenly have more privileged people who have the luxury to spend that time, learn more, do things.
What does “Chocolate Milk Cult Leader” mean?
James Wang
Yeah, totally. Well, in terms of this, guess to end on a different note, maybe the most important question of the podcast here, what does Chocolate Milk Cult Leader mean exactly?
Devansh
So for context, James' audience, that's what I call myself on LinkedIn and everywhere else.
So it comes from two different parts. The chocolate milk part comes from the fact that when I started writing, it's not like I enjoy writing about AI research. It's not a lot of fun. And at that point, it's not like I thought this would become a career or whatnot. So I had to find motivations to get myself to write. And the two motivations I picked out were music. So I love music. I would only listen to music when I was writing or doing something else that's productive. And drinking chocolate milk, I would only drink chocolate milk when I was writing specifically.
This was also from making YouTube videos… that was actually one of my original motivations. So if you look at a lot of my earlier YouTube videos, I made YouTube videos, you'll see me drinking milk when I'm speaking because that was my motivation to do it. So that's where the chocolate milk part comes in from.
The cult leader, when I was in university, I was accused of trying to start a cult. This, by the way, is untrue. I was trying to start a religion, not a cult. But we used to gather a bunch of people. I used to climb a tree, I tried convincing strangers to get into the tree with me. My record for that is 19, which I still think is my greatest achievement.
Because I don't know you've tried this, but if you're a stranger, screaming out at people at late Friday nights, trying to get them in a tree with you, people aren't normally very receptive to that. Especially when they can't see you. You're just a voice in the tree. Specifically, like a voice with an Indian accent in the tree. It's not exactly the most... it’s not the easiest pitch to get them to climb a tree with you. But we managed to get 19 people in that tree with me. God bless, we got two girls to do it, because then they screamed a lot for me from the tree and we got a lot of guys in because of that.
So a few different people thought I was trying to start a cult. I just wanted to start a religion. I thought it would be cool. I thought I could get some tax benefits and see if I could get some money from my university that way, etcetera. Didn't go anywhere because it's very hard for a non-citizen to start a religion in America.
So that's another reason why I wanted IQIDIS to succeed is so I can finally get all the paperwork done. But that's where the name comes from. To blend into the integral parts of my life.
James Wang
You heard it here, both the ways of motivating yourself and a message that in America it's too hard to start a religion if you are exiled. So yeah, good stuff. Thanks so much, Devansh. This was great.
Devansh
Yeah. I had a good time. Thank you for having me, James. It's an absolute honour.
Thanks for reading!
I hope you enjoyed this article. If you’d like to learn more about AI’s past, present, and future in an easy to understand way, I’m working on a book titled What You Need to Know About AI that will be published October 15th.
You can learn more about it and pre-order on Amazon, Barnes and Noble, or Bookshop (indie booksellers).

